原文:《Elasticsearch笔记(六):Search Module》
搜索允许您执行搜索查询并返回与查询匹配的搜索结果。可以使用query string as a parameter,也可以使用request body。其中request body和Query DSL功能最为强大,最为复杂。在未展开论述前,先讲会一个概念:近实时搜索。
前面讲过只有get API是实时的,搜索是逐段进行的。我们都知道一个index是由若干个segment组成,随着每个segment的不断增长,我们索引一条数据后可能要经过分钟级别的延迟才能被搜索,为什么有种这么大的延迟,这里面的瓶颈点主要在磁盘。持久化一个segment需要fsync操作用来确保segment能够物理的被写入磁盘以真正的避免数据丢失,但是fsync操作比较耗时,所以它不能在每索引一条数据后就执行一次,如果那样索引和搜索的延迟都会非常之大。所以在es中新增的document会被收集到indexing buffer区后被重写成一个segment然后直接写入filesystem cache中,这个操作是非常轻量级的,相对耗时较少,之后经过一定的间隔或外部触发后才会被flush到磁盘上,这个操作非常耗时。但只要sengment文件被写入cache后,这个sengment就可以打开和查询,从而确保在短时间内就可以搜到,而不用执行一个full commit也就是fsync操作,这是一个非常轻量级的处理方式而且是可以高频次的被执行,而不会破坏es的性能。这个轻量级的写入和打开一个cache中的segment的操作叫做refresh,默认情况下,es集群中的每个shard会每隔1秒自动refresh一次,这就是我们为什么说es是近实时的搜索引擎而不是实时的。
目录
2.8.5 TReturning the type of the suggester
3.4.3 match phrase prefix query
3.4.7 simple query string query
1. 搜索流程
当一个搜索请求被发送到某个节点时,这个节点就变成了协调节点。 这个节点的任务是广播查询请求到所有相关分片并将它们的响应整合成全局排序后的结果集合,这个结果集合会返回给客户端。在上一节讲过【取回一个文档的流程】。多索引搜索恰好也是用相同的方式-只是会涉及到更多的分片。
查询阶段
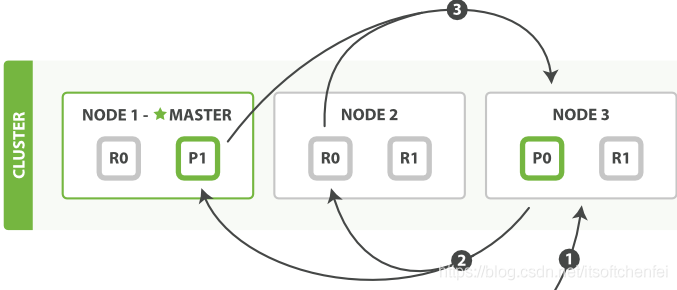
客户端发送一个 search 请求到 Node 3 , Node 3 会创建一个大小为 from + size 的空优先队列。
Node 3 将查询请求转发到索引的每个主分片或副本分片中。每个分片在本地执行查询并添加结果到大小为 from + size 的本地有序优先队列中。
每个分片返回各自优先队列中所有文档的 ID 和排序值给协调节点,也就是 Node 3 ,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
取回阶段
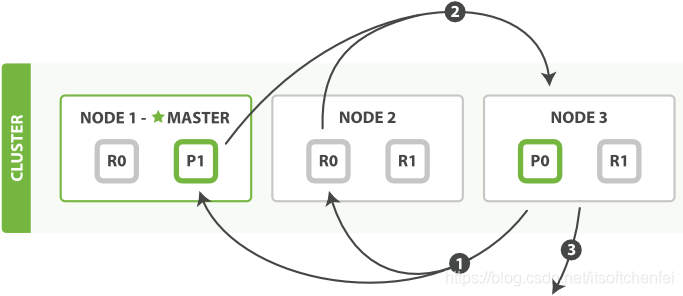
协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求(每个分片创建一个 multi-get request)。例如,如果我们的查询指定了 { "from": 90, "size": 10 } ,最初的90个结果会被丢弃,只有从第91个开始的10个结果需要被取回。
每个分片加载并丰富(元数据和高亮显示)文档,如果有需要的话,接着返回文档给协调节点。
一旦所有的文档都被取回了,协调节点返回结果给客户端。
注意:搜索一个索引有五个主分片和搜索五个索引各有一个分片准确来所说是等价的。
![]()
![]() 2. search API
2. search API
![]()
![]() 2.1 multi index/type
2.1 multi index/type
GET /_search //搜索所有的索引中所有的类型
GET /alibaba/_search //在alibaba索引中搜索所有的类型
GET /alibaba,kxtx/_search //在alibaba和kxtx索引中中搜索所有的文档
GET /m*,k*/_search //在任何以m或者k开头的索引中搜索所有的类型
GET /alibaba/employee/_search //在alibaba索引中搜索employee类型
GET /gb,us/user,tweet/_search //在gb和us索引中搜索user和tweet类型
GET /_all/user,tweet/_search //在所有的索引中搜索user和tweet 类型
![]()
![]() 2.2 search结果解析
2.2 search结果解析
{
"hits" : { //最重要的部分
"total" : 14, //匹配到的文档总数
"hits" : [ //文档结果集
{
"_index": "us",
"_type": "tweet",
"_id": "7",
"_score": 1, //它衡量了文档与查询的匹配程度,默认是按照_score降序排列的
"_source": { //原始文档
"date": "2014-09-17",
"name": "John Smith",
"tweet": "The Query DSL is really powerful and flexible",
"user_id": 2
}
},
... 9 RESULTS REMOVED ...
],
"max_score" : 1 //与查询所匹配文档的_score的最大值
},
"took" : 4, //整个请求耗费了多少毫秒
"_shards" : { //查询中参与分片的总数
"failed" : 0, //正常情况下我们不希望分片失败,但是分片失败是可能发生的(遭遇到一种灾难级别的故障:丢失了相同分片的原始数据和副本)
"successful" : 10,
"total" : 10
},
"timed_out" : false //查询是否超时,默认情况下,搜索请求不会超时
}
![]()
![]() _score 详解
_score 详解
相似度算法被定义为检索词频率(检索词在该字段出现的频率)/反向文档频率(检索词在索引中出现的频率),即TF/IDF和字段长度准则(长度越长,相关性越低)。 相关性得分由一个浮点数进行表示,通过_score 参数返回,默认排序是_score降序。
有时候精确匹配,相关性评分对你来说并没有意义,它默认会返回0。但如果评分为零对你造成了困扰,可以使用constant_score查询进行替代,它会返回恒定分数(默认为 1 )。
计算_score的花销巨大,通常仅用于排序;我们并不根据相关性排序,那它没有意义的。如果无论如何你都要计算_score,你可以将track_scores参数设置为true。
![]()
![]() 2.3 URI Search
2.3 URI Search
URI 搜索方式通过URI参数来指定查询相关参数。
GET /alibaba/employee/_search?q=last_name:Smith //精确 where last_name like '%Smith%'
GET /website/_search?q=+name:trying +date:2014 //where name like '%trying%' or date like '%2014%',+前缀表示必须与查询条件匹配
![]()
![]() 参数说明
参数说明
| q | 查询字符串,映射到query_string字段值(Query Dsl String Query) |
| analyzer | 分析查询字符串时要使用的分析器名称 |
| sort | 排序以执行,可以是fieldname的形式,也可以是fieldname:asc/fieldname:desc的形式 |
| timeout | 搜索超时,限定要在指定的时间值内执行的搜索请求,并在到期时将命中累积到该时间点。 timeout不是停止执行查询,它仅仅是告知正在协调的节点返回到目前为止收集的结果并且关闭连接,在后台,其他的分片可能仍在执行查询即使是结果已经被发送了。 默认为无超时。如果觉得麻烦,它支持全局超时配置。 |
| from | 要返回的点击量的起始索引。默认值为0。 |
| size | 要返回的命中数。默认值为10。 |
| search_type | 查询的执行方式,可选值dfs_query_then_fetch or query_then_fetch ,默认: query_then_fetch,它有预查询阶段(从所有相关分片获取词频来计算全局词频)会破坏相关度,缺省值只在主分片上计算相关度 |
| 更多 |
![]()
![]() 2.4 Request Body Search
2.4 Request Body Search
Request body 搜索方式以JSON格式在请求体中定义查询query。
GET /twitter/_search
{
"query" : {
"term" : { "user" : "kimchy" }
}
}
![]()
![]() 参数说明
参数说明
| timeout | 略(讲过) |
| from | 略 |
| size | 略 |
| request_cache | 是否缓存请求结果,默认true |
| terminate_after | 限定每个分片取几个文档。如果设置,则响应将有一个布尔型字段terminated_early来指示查询执行是否实际已经terminate_early。缺省为no |
| batched_reduce_size | 一次在协调节点上应该减少的分片结果的数量。如果请求中的潜在分片数量可能很大,则应将此值用作保护机制以减少每个搜索请求的内存开销。 |
| 更多 |
![]()
![]() 丰富的特性
丰富的特性
| From / Size | 支持分页查询,请注意,From+Size不能超过index.max_result_window索引设置,默认值为10000。在分布式系统中,对结果排序的成本随分页的深度成指数上升。这就是web搜索引擎对任何查询都不要返回超过1000个结果的原因:假设在一个有5个主分片的索引中搜索,size=10(每一个分片产生前10的结果,返回给协调节点,协调节点对50个结果排序得到全部结果的前10个),size=10&from=10(每个分片不得不产生前10010个结果,然后协调节点对全部 50050 个结果排序最后丢弃掉这些结果中的50040个结果)。要解决它,请参阅scroll或search after api以获得更有效的深度滚动方法。 GET /_search |
| Sort | 可以指定按一个或多个字段排序。也可通过_score指定按评分值排序,_doc 按索引顺序排序。默认是按相关性评分从高到低排序。对于值是数组或多值的字段,也可进行排序,通过mode参数指定按多值的(min/max/sum/avg/median)。 GET /bank/_search |
| Source filtering | 对返回的_source字段进行选择 GET /_search |
| Fields | 指定返回哪些stored字段,* 可用来指定返回所有存储字段 GET /_search |
| Script Fields | 用脚本来对命中的每个文档的字段进行运算后返回 GET /bank/_search |
| Doc value Fields | 返回存储了doc Value的字段值,文档值是一种磁盘上的数据结构,以面向列的方式存储,这对于排序和聚合有效。 GET /_search |
| Post filter | 后置过滤:在查询命中文档、完成聚合后,再对命中的文档进行过滤 {"query": { 还有一个对应的反向的操作,filtered(先过滤再查询,速度快),不过已废弃。 { "query": { |
| Highlighting | 高亮显示 |
| Rescoring | 目前,rescore API只有一个实现:rescorer查询,它使用查询来调整评分。在将来,可提供替代的再订阅者,例如,成对的再订阅者。rescorer查询 仅对查询和后筛选阶段返回的top-k结果执行第二个查询。每个分片上要检查的文档数可以由window_size参数控制,该参数默认为10。默认情况下,原始查询和rescorer存储查询的分数是线性组合的,以生成每个文档的最终分数。原始查询和rescorer查询的相对重要性可以分别通过查询权重和rescorer查询权重来控制。两者都默认为1。 POST /_search |
| Search Type | 略(讲过) |
| Scroll | 与在传统数据库中使用光标的方式非常相似(游标查询允许我们先做查询初始化,然后再批量地拉取结果)。Scroll可以有效地执行大批量的文档查询,而又不用付出深度分页那种代价。它仅仅从还有结果的分片返回下一批结果。 游标查询会取某个时间点的快照数据,查询初始化之后索引上的任何变化会被它忽略。 深度分页的代价根源是结果集全局排序,如果去掉话查询结果的成本就会很低。游标查询用字段_doc 来排序。 GET /old_index/_search?scroll=1m //保持游标查询窗口一分钟 |
| Preference | 选择在那些分片上执行查询,它有_primary、_primary_first、_replica.. |
| Explain | 对每次命中的分数计算方式启用解释 GET /_search |
| Version | 指定返回文档的版本字段 GET /_search |
| Index Boost | 允许在搜索多个索引时为每个索引配置不同的boost level。当来自一个索引的点击比来自另一个索引的点击更重要时(想想每个用户都有一个索引的社交图),这非常方便 |
| min_score | 限制最低评分得分 GET /_search |
| Named Queries | 每个过滤器和查询可以在其顶级定义中接受一个名称。 GET /_search |
| Inner hits | 父联接和嵌套功能允许返回在不同范围内具有匹配项的文档。 |
| Field Collapsing | 用 collapse指定根据某个字段对命中结果进行折叠 |
| Search After | 在指定文档后取文档, 可用于深度分页 GET twitter/_search 注意:使用search_after,要求查询必须指定排序,并且这个排序组合值每个文档唯一(最好排序中包含_id字段)。 search_after的值用的就是这个排序值。 用search_after时 from 只能为0、-1。 |
![]()
![]() 2.5 Search Template
2.5 Search Template
/_search/template端点允许使用 mustache language 预先呈现搜索请求,然后执行它们并使用模板参数填充现有模板。比较小众,不展开讲。
![]()
![]() 2.6 Multi Search Template
2.6 Multi Search Template
多搜索模板API允许使用_msearch/template端点在同一API内执行多个搜索模板请求,是search template的批量。
![]()
![]() 2.7 Search Shards
2.7 Search Shards
搜索分片api返回将执行搜索请求的索引和分片。这可以为解决问题或使用路由和分片首选项规划优化提供有用的反馈。索引可以是单个值,也可以是逗号分隔的。
GET /twitter/_search_shards
GET /twitter/_search_shards?routing=foo,baz
![]()
![]() 参数说明
参数说明
| routing | 以逗号分隔的路由值列表,在确定将对哪些分片执行时要考虑 |
| preference | 控制哪个分片复制副本执行搜索请求的首选项。默认情况下,操作在分片的副本之间随机化 |
| local | 布尔值是否在本地读取集群状态以确定分配分片的位置而不是使用主节点的集群状态 |
![]()
![]() 2.8 查询建议
2.8 查询建议
查询建议,为用户提供良好的使用体验。主要包括: 拼写检查; 自动建议查询词(自动补全)
POST twitter/_search
{
"query" : {
"match": {
"message": "tring out Elasticsearch"
}
},
"suggest" : {
"my-suggestion" : { //一个建议查询名
"text" : "tring out Elasticsearch", //查询文本
"term" : { //使用词项建议
"field" : "message" //指定在哪个字段上获取建议词
}
}
}
}
![]()
![]() 2.9.1 词项建议
2.9.1 词项建议
Term suggester,对给入的文本进行分词,为每个词进行模糊查询提供词项建议。对于在索引中存在词默认不提供建议词,不存在的词则根据模糊查询结果进行排序后取一定数量的建议词。
参数说明
| text | 搜索文字。搜索文字是必需的选项,需要全局或按建议设置。 |
| field | 搜索的字段,这是一个必需的选项,需要全局设置或根据建议设置。 |
| analyzer | 指定的分析器,默认为搜索的字段的分析器。 |
| size | 每个词返回的最大建议词数 |
| sort | 如何对建议词进行排序,选项: score :先按score排序,然后按文档频率排序,再按term本身排序 frequency:先按文件频率排序,然后按相似性得分排序,再按term本身排序 |
| suggest_mode | 建议模式,选项: missing:仅在搜索的词项在索引中不存在时才提供建议。这是默认值。 popular:仅建文档频率比搜索词项高的词。 always:总是提供匹配的建议词 |
| 更多 |
![]()
![]() 2.8.2 短语建议
2.8.2 短语建议
phrase suggester,在term的基础上,会考量多个term之间的关系,比如是否同时出现在索引的原文里,相邻程度,以及词频等
POST /product/_search
{
"query": {
"match_all": {}
},
"suggest" : {
"myss":{
"text": "spring boot",
"phrase": {
"field": "title"
}
}
}
}
direct_generator参数说明
| field | 略(讲过) |
| size | 略 |
| suggest_mode | 略 |
| 更多 |
![]()
![]() 2.8.3 自动补全
2.8.3 自动补全
Completion suggester,针对自动补全场景而设计的建议器。此场景下用户每输入一个字符的时候,就需要即时发送一次查询请求到后端查找匹配项,在用户输入速度较高的情况下对后端响应速度要求比较苛刻。因此实现上它和前面两个Suggester采用了不同的数据结构,索引并非通过倒排来完成,而是将analyze过的数据编码成FST和索引一起存放。对于一个open状态的索引,FST会被ES整个装载到内存里的,进行前缀查找速度极快。但是FST只能用于前缀查找,这也是Completion Suggester的局限所在。completion suggester用法大概有三种,最常规的就是前缀查询(prefix),其次是模糊查询(fuzzy)和正则表达式查询(regex)
PUT music
{
"mappings": {
"_doc" : {
"properties" : {
"suggest" : {
"type" : "completion"
},
"title" : {
"type": "keyword"
}
}
}
}
}
PUT music/_doc/1?refresh
{
"suggest" : [
{
"input": "Nevermind",
"weight" : 10 //指定输入词 Weight 指定排序值
},
{
"input": "Nirvana",
"weight" : 3
}
]}
PUT music/_doc/2?refresh
{
"suggest" : {
"input": [ "Nevermind", "Nirvana" ],
"weight" : 20
}
}
POST music/_search?pretty
{
"suggest": {
"song-suggest" : {
"prefix" : "nir", //查询建议根据前缀查询
"completion" : {
"field" : "suggest"
}
}
}
}
POST music/_search?pretty
{
"suggest" : {
"song-suggest" : {
"prefix" : "nir",
"completion" : {
"field" : "suggest",
"skip_duplicates" : true //对建议查询结果去重
}
}
}
}
![]()
![]() 2.8.4 Context suggester
2.8.4 Context suggester
略
![]()
![]() 2.8.5 TReturning the type of the suggester
2.8.5 TReturning the type of the suggester
有时您需要知道建议器的确切类型才能解析其结果。typed_keys参数可用于更改响应中的建议者名称,以使其以其类型为前缀。
POST _search?typed_keys
{
"suggest": {
"text" : "some test mssage",
"my-first-suggester" : {
"term" : {
"field" : "message"
}
},
"my-second-suggester" : {
"phrase" : {
"field" : "message"
}
}
}
}
![]()
![]() 2.9 Multi Search API
2.9 Multi Search API
多搜索API允许在同一API中执行多个搜索请求。
语法:
header\n
body\n
header\n
body\nGET twitter/_msearch
{}
{"query" : {"match_all" : {}}, "from" : 0, "size" : 10}
{}
{"query" : {"match_all" : {}}}
{"index" : "twitter2"}
{"query" : {"match_all" : {}}}
![]()
![]() 2.10 Count API
2.10 Count API
GET /twitter/_doc/_count?q=user:kimchy
GET /twitter/_doc/_count
{
"query" : {
"term" : { "user" : "kimchy" }
}
}
![]()
![]() 2.11 Validate API
2.11 Validate API
验证API用来检查我们的查询是否正确,以及查看底层生成查询是怎样的
GET twitter/_validate/query?q=user:foo
GET twitter/_doc/_validate/query //校验查询
{
"query": {
"query_string": {
"query": "post_date:foo",
"lenient": false
}
}
}
GET twitter/_doc/_validate/query?explain=true //获得查询解释
{
"query": {
"query_string": {
"query": "post_date:foo",
"lenient": false
}
}
}
GET twitter/_doc/_validate/query?rewrite=true //用rewrite获得比explain 更详细的解释
{
"query": {
"more_like_this": {
"like": {
"_id": "2"
},
"boost_terms": 1
}
}
}
GET twitter/_doc/_validate/query?rewrite=true&all_shards=true //获得所有分片上的查询解释
{
"query": {
"match": {
"user": {
"query": "kimchy",
"fuzziness": "auto"
}
}
}
}
![]()
![]() 2.12 Explain API
2.12 Explain API
explain 获得某个查询的评分解释,及某个文档是否被这个查询命中
GET /twitter/_doc/0/_explain?q=message:search
GET /twitter/_doc/0/_explain
{
"query" : {
"match" : { "message" : "elasticsearch" }
}
}
![]()
![]() 2.13 Profile API
2.13 Profile API
Profile 为了调试、优化,对于执行缓慢的查询,我们很想知道它为什么慢,时间都耗在哪了,可以在查询上加入上 profile 来获得详细的执行步骤、耗时信息。它的用法有:Profiling Queries、Profiling Aggregations、Profiling Considerations 。
GET /twitter/_search
{
"profile": true,
"query" : {
"match" : { "message" : "some number" }
}
}
![]()
![]() 2.14 Field Capabilities API
2.14 Field Capabilities API
它允许检索某个字段在多个索引中的功能(searchable=true、aggregatable=true、indices(哪些包含它))。
GET _field_caps?fields=rating,title
![]()
![]() 2.15 排名评估API
2.15 排名评估API
Ranking Evaluation API,它是实验性的,可以在将来的版本中完全更改或删除,先不关注。
![]()
![]() 3. Query DSL
3. Query DSL
![]()
![]() 3.1 介绍
3.1 介绍
ES提供基于JSON的完整查询DSL(域特定语言)来定义查询。将Query DSL视为查询的AST(抽象语法树),由两种类型的子句组成:
Leaf query clauses,叶子查询字句,在指定的字段上查询指定的值, 如:match, term or range queries。叶子字句可以单独使用。
Compound query clauses,复合查询字句,以逻辑方式组合多个叶子、复合查询为一个查询
{//典型语法结构
QUERY_NAME: { // match、match_all
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
{//针对某个字段语法结构
QUERY_NAME: {//query
FIELD_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
}
![]()
![]() 3.2 Query and filter context
3.2 Query and filter context
一个查询字句的行为取决于它是用在query context 还是 filter context 中。查询和过滤都是对所有文档进行查询,最后两个结果取交集。
| Query context | 查询上下文,用在查询上下文中的字句回答“这个文档有多匹配这个查询?”。除了决定文档是否匹配,字句匹配的文档还会计算一个字句评分,来评定文档有多匹配。查询上下文由 query 元素表示。 查询器有: |
| Filter context | 过滤上下文,过滤上下文由 filter 元素或 bool 中的 must not 表示。用在过滤上下文中的字句回答“这个文档是否匹配这个查询?”,过滤语句的目的就是缩小匹配的文档结果集,不参与相关性评分。被频繁使用的过滤器将被ES自动缓存,来提高查询性能。 过滤器有: |
复合查询语句可以加入其它查询子句,复合过滤子句也可以加入其它过滤子句。 通常情况下,一条查询语句需要过滤语句的辅助,全文本搜索除外。 |
过滤器的操作
1.非评分查询,当我们不关心检索词频率TF(_score)对搜索结果排序的影响时,可以使用constant_score将查询语句query或者过滤语句filter包装起来
2.非评分查询执行流程
step1:查找匹配文档,term查询在倒排索引中查找XHDK-A-1293-#fJ3然后获取包含该term的所有文档
step2:创建 bitset,过滤器会创建一个 bitset(一个包含0和1的数组),它描述了哪个文档会包含该term
step3:迭代 bitset(s),一旦为每个查询生成了bitset,es就会循环迭代bitset从而找到满足所有过滤条件的匹配文档的集合,一般来说先迭代稀疏的 bitset(因为它可以排除掉大量的文档)
step4:增量使用计数,es能够缓存非评分查询从而获取更快的访问,但是它也会不太聪明地缓存一些使用极少的东西。为了只想缓存那些我们知道在将来会被再次使用的查询,以避免资源的浪费,ES会为每个索引跟踪保留查询使用的历史状态。如果查询在最近的 256 次查询中会被用到,那么它就会被缓存到内存中。当bitset被缓存后,缓存会在那些低于 10,000 个文档(或少于 3% 的总索引数)的段(segment)中被忽略。这些小的段即将会消失,所以为它们分配缓存是一种浪费。
3.理论上非评分查询先于评分查询执行。非评分查询任务旨在降低那些将对评分查询计算带来更高成本的文档数量,从而达到快速搜索的目的。缓存
过滤器核心实际是采用一个bitset记录与过滤器匹配的文档,es积极地把这些bitset缓存起来以备随后使用。bitsets缓存是“智能”(过滤器是实时的,我们无需担心缓存过期问题):它们以增量方式更新。当我们索引新文档时,只需将那些新文档加入已有 bitset,而不是对整个缓存一遍又一遍的重复计算。bitsets 在内存的存储是独立于query的,有很强的复用性。bitsetcache在内存里面, 永不消失(除非被LRU)。善用filtered query
理解lucence filter工作原理对于高性能查询语句至关重要。 filter使用bitsets进行布尔运算, quey使用倒排索引进行计算, 这是filter比query快的原因。能用filter就用filter, 除非必须使用query(当且仅当你需要算分的时候)。
GET /_search
{
"query": { //查询
"bool": {
"must": [
{ "match": { "title": "Search" }},
{ "match": { "content": "Elasticsearch" }}
],
"filter": [ //过滤
{ "term": { "status": "published" }},
{ "range": { "publish_date": { "gte": "2015-01-01" }}}
]
}
}
}
![]()
![]() 3.3 Match all
3.3 Match all
Match All Query,查询所有,相关性分值(_score)为1
GET /_search
{
"query": {
"match_all": {}
}
}
GET /_search
{
"query": {
"match_none": {} //相反,什么都不查
}
}
![]()
![]() 3.4 全文查询
3.4 全文查询
Full text queries,全文查询,用于对分词的字段进行搜索。会用查询字段的分词器对查询的文本进行分词生成查询。可用于短语查询、模糊查询、前缀查询、临近查询等查询场景
![]()
![]() 3.4.1 match query
3.4.1 match query
Match Query,它可以对一个字段进行模糊、短语查询。 match queries 接收 text/numerics/dates, 对它们进行分词分析(如果在一个精确值的字段上使用它,例如数字、日期、布尔或者一个not_analyzed字符串字段,那么它将会精确匹配给定的值), 再组织成一个boolean查询。
可通过operator 指定bool组合操作(or、and 默认是 or )。还可用ananlyzer指定查询用的特殊分析器。
控制精度,在所有与任意间二选一有点过非黑即白,match查询支持minimum_should_match指定至少需多少个(数字或百分比))should(or)字句需满足,因为我们无法控制用户搜索时输入的单词数量建议采用百分比。
它评分的计算方式, bool 查询运行每个 match 查询,再把评分加在一起,然后将结果与所有匹配的语句数量相乘,最后除以所有的语句数量。
GET /_search
{
"query": {
"match" : {
"title" : "this is a test"
}
}
}
GET ftq/_search
{
"query": {
"match": {
"title": {
"query": "lucene java",
"operator": "and", //也可以指定操作符
"minimum_should_match": 2 //指定最少需满足两个词匹配
}
}
}
}
![]()
![]() 3.4.2 match phrase query
3.4.2 match phrase query
Match Phrase Query,查询用来对一个字段进行短语查询,可以指定 analyzer、slop移动因子。
GET ftq/_search
{
"query": {
"match_phrase": {
"title": "lucene solr"
}
}
}
![]()
![]() 3.4.3 match phrase prefix query
3.4.3 match phrase prefix query
Match Phrase Prefix Query,它在 match_phrase 的基础上支持对短语的最后一个词进行前缀匹配
GET /_search
{
"query": {
"match_phrase_prefix" : {
"message" : "quick brown f"
}
}
}
![]()
![]() 3.4.4 multi match query
3.4.4 multi match query
Multi Match Query,如果你需要在多个字段上进行文本搜索,可用multi_match 。 multi_match在 match的基础上支持对多个字段进行文本查询。
GET ftq/_search
{
"query": {
"multi_match" : {
"query": "lucene java",
"fields": [ "title", "content" ]
}
}
}
GET ftq/_search
{
"query": {
"multi_match" : {
"query": "lucene java",
"fields": [ "title", "cont*" ] //字段通配符查询
}
}
}
GET ftq/_search?explain=true
{
"query": {
"multi_match" : {
"query": "lucene elastic",
"fields": [ "title^5", "content" ] //给字段的相关性评分加权重
}
}
}
![]()
![]() 3.4.5 Common terms query
3.4.5 Common terms query
Common Terms Query,常用词查询,common 区分常用(高频)词查询让我们可以通过cutoff_frequency来指定一个分界文档频率值,将搜索文本中的词分为高频词和低频词,低频词的重要性高于高频词,先对低频词进行搜索并计算所有匹配文档相关性得分;然后再搜索和高频词匹配的文档,这会搜到很多文档,但只对和低频词重叠的文档进行相关性得分计算(这可保证搜索精确度,同时大大提高搜索性能),和低频词累加作为文档得分。实际执行的搜索是 必须包含低频词 + 或包含高频词。
思考:这样处理下,如果用户输入的都是高频词如 “to be or not to be”结果会是怎样的?你希望是怎样的?如果都是高频词,那就对这些词进行and 查询。还进一步优化,让用户可以自己定对高频词做and/or 操作,自己定对低频词进行and/or 操作;或指定最少得多少个同时匹配。
GET /_search
{
"query": {
"common": {
"message": {
"query": "this is bonsai cool",
"cutoff_frequency": 0.001 // 值大于1表示文档数,0-1.0表示占比,此处界定文档频率大于 0.1%的词为高频词
}
}
}
}
GET /_search
{
"query": {
"common": {
"body": {
"query": "nelly the elephant as a cartoon",
"cutoff_frequency": 0.001,
"low_freq_operator": "and" //指定对低频词做与操作
}
}
}
}
![]()
![]() 3.4.6 query string query
3.4.6 query string query
Query String Query,让我们可以直接用lucene查询语法写一个查询串进行查询,ES中接到请求后,通过查询解析器解析查询串生成对应的查询。使用它要求掌握lucene的查询语法。
GET /_search
{
"query": {
"query_string" : {
"default_field" : "content", //指定单个字段查询
"query" : "this AND that OR thus"
}
}
}
GET /_search
{
"query": {
"query_string" : {
"fields" : ["content", "name.*^5"], //指定多字段通配符查询
"query" : "this AND that OR thus"
}
}
}
![]()
![]() 3.4.7 simple query string query
3.4.7 simple query string query
Simple Query String Query,查同 query_string 查询一样用lucene查询语法写查询串,较query_string不同的地方:更小的语法集;查询串有错误,它会忽略错误的部分,不抛出错误。更适合给用户使用。
GET /_search
{
"query": {
"simple_query_string" : {
"query": "\"fried eggs\" +(eggplant | potato) -frittata",
"fields": ["title^5", "body"],
"default_operator": "and"
}
}
}
![]()
![]() 3.5 词级别查询
3.5 词级别查询
Term level queries,虽然全文查询将在执行之前分析查询字符串,但是 term-level 查询对存储在反向索引中的确切术语进行操作,并且在仅针对 normalizer 属性的 keyword字段(not_analyzed的字符串)执行之前将规范化词。这些查询通常用于结构化数据,如数字,日期和枚举,而不是全文字段。或者,它们允许您在分析过程之前制定低级查询。
![]()
![]() 3.5.1 term查询
3.5.1 term查询
Term Query,用于查询指定字段包含某个词项的文档。
POST _search
{
"query": {
"term" : { "user" : "Kimchy" }
}
}
GET _search
{
"query": {
"bool": {
"should": [
{
"term": {
"status": {
"value": "urgent",
"boost": 2 //加权重
}
}
},
{
"term": {
"status": "normal"
}
}
]
}
}
}
![]()
![]() 3.5.2 terms 查询
3.5.2 terms 查询
Terms Query,用于查询指定字段包含某些词项的文档。term与terms的区别在于:es dsl解释器会将terms拆成多个term的OR处理(termsQuery 等效为多个 termQuery 使用 boolQuery 使用 or 操作符连接起来)。
GET /_search
{
"query": {
"terms" : { "user" : ["kimchy", "elasticsearch"]}
}
}
PUT /users/_doc/2
{
"followers" : ["1", "3"]
}
PUT /tweets/_doc/1
{
"user" : "1"
}
GET /tweets/_search
{
"query": {
"terms": {
"user": { //嵌套查询,相当于 in (select term from other)
"index": "users",
"type": "_doc",
"id": "2",
"path": "followers"
}
}
}
}
![]()
![]() 3.5.3 terms set query
3.5.3 terms set query
Terms Set Query,terms_set查询是一个新查询,其语法可能在将来发生变化,可忽略
GET /my-index/_search
{
"query": {
"terms_set": {
"codes" : {
"terms" : ["abc", "def", "ghi"],
"minimum_should_match_field": "required_matches"
}
}
}
}
![]()
![]() 3.5.4 范围查询
3.5.4 范围查询
Range Query,Lucene查询的类型取决于字段类型,对于字符串字段,TermRangeQuery,而对于数字/日期字段,查询是NumericRangeQuery。
| Greater-than or equal to |
| Greater-than |
| Less-than or equal to |
| Less-than |
| Sets the boost value of the query, defaults to |
Date类型使用上有些差别
| Greater than the date rounded up: |
| Greater than or equal to the date rounded down: |
| Less than the date rounded down: |
| Less than or equal to the date rounded up: |
GET _search
{
"query": {
"range" : {
"age" : {
"gte" : 10,
"lte" : 20,
"boost" : 2.0
}
}
}
}
GET _search
{
"query": {
"range" : {
"born" : {
"gte": "01/01/2012",
"lte": "2013",
"format": "dd/MM/yyyy||yyyy"
}
}
}
}
![]()
![]() 3.5.5 exists
3.5.5 exists
Exists Query,有值(exists)或无值(missing) ,exists相当 SQL 中的 column is not null。missing代表缺少字段或null值,属于聚合操作。但是missing在6.x版本已经移除。
GET /_search
{
"query": {
"exists" : { "field" : "user" }
}
}
GET /_search //可以代表missing的意思
{
"query": {
"bool": {
"must_not": {
"exists": {
"field": "user"
}
}
}
}
}
![]()
![]() 3.5.6 前缀查询
3.5.6 前缀查询
Prefix Query,基于词条,前缀查询映射到Lucene PrefixQuery。
GET /_search
{ "query": {
"prefix" : { "user" : "ki" }
}
}
GET /_search
{ "query": {
"prefix" : { "user" : { "value" : "ki", "boost" : 2.0 } } //加权
}
}
![]()
![]() 3.5.7 通配符查询
3.5.7 通配符查询
Wildcard Query,基于词条,匹配具有(not analyzed)的字段的文档,它使用标准的 shell 通配符查询: ? 匹配任意字符, * 匹配 0 或多个字符。请注意,此查询可能很慢,因为它需要迭代多个词。为了防止极慢的通配符查询,通配符术语不应该以通配符*或?之一开头。通配符查询映射到Lucene WildcardQuery
GET /_search
{
"query": {
"wildcard" : { "user" : "ki*y" }
}
}
![]()
![]() 3.5.8 正则查询
3.5.8 正则查询
Regexp Query,基于词条,正则表达式查询的性能在很大程度上取决于所选的正则表达式。匹配像 .* 这样的所有内容非常慢,并且使用环绕正则表达式。如果可能,您应该在正则表达式开始之前尝试使用长前缀。像 .* ?+这样的通配符匹配器会降低性能。
GET /_search
{
"query": {
"regexp":{
"name.first": "s.*y"
}
}
}
prefix,wildcard以及regexp使用上有何区别?在我的另一篇有讲
![]()
![]() 3.5.9 纠错查询
3.5.9 纠错查询
Fuzzy Query,fuzziness的默认值是2 (表示最多可以纠错两次),fuzziness的值太大, 将削弱查询串的作用, 也就是说, 纠错太多, 导致限定查询结果的串被改变, 失去了限定作用
GET shop/_search
{
"query": {
"match": {
"name": {
"query": "Jav", //Java中缺失了一个字母a
"fuzziness": 1,
"operator": "and"
}
}
}
}
![]()
![]() 3.5.10 type query
3.5.10 type query
Type Query,mapping type 查询
GET /_search
{
"query": {
"type" : {
"value" : "_doc"
}
}
}
![]()
![]() 3.5.11 id查询
3.5.11 id查询
Ids Query,根据文档id查询
GET /_search
{
"query": {
"ids" : {
"type" : "_doc",
"values" : ["1", "4", "100"]
}
}
}
![]()
![]() 3.6 复合查询
3.6 复合查询
Compound queries,复合查询包装其他复合或叶子查询,以组合其结果和分数,更改其行为,或从查询切换到筛选器上下文。
![]()
![]() 3.6.1 常数分查询
3.6.1 常数分查询
Constant Score Query,用来包装另一个查询,将查询匹配的文档的评分设为一个常值。映射到Lucene ConstantScoreQuery,采用非评分查询性能会更好。
GET /_search
{
"query": {
"constant_score" : {
"filter" : {
"term" : { "user" : "kimchy"}
},
"boost" : 1.2
}
}
}
![]()
![]() 3.6.2 Bool查询
3.6.2 Bool查询
Bool Query,Bool 查询用bool操作来组合多个查询字句为一个查询。映射Lucene BooleanQuery。
bool查询与bool过滤器一个重要的区别,过滤器做二元判断:文档是否应该出现在结果中?但查询更精妙,它除了决定一个文档是否应该被包括在结果中,还会计算文档的相关程度。
bool 查询会为每个文档计算相关度评分 _score , 再将所有匹配的 must 和 should 语句的分数 _score 求和,最后除以 must 和 should 语句的总数。
可用的关键字:
| 与AND等价,并有助于得分 |
| 必须匹配,但它在 Filter上下文中执行,不影响评分 |
| 与OR等价 |
| 与NOT等价,在 Filter上下文中执行,不影响评分 |
POST _search
{
"query": {
"bool" : {
"must" : {
"term" : { "user" : "kimchy" }
},
"filter": {
"term" : { "tag" : "tech" }
},
"must_not" : {
"range" : {
"age" : { "gte" : 10, "lte" : 20 }
}
},
"should" : [
{ "term" : { "tag" : "wow" } },
{ "term" : { "tag" : "elasticsearch" } }
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}
GET _search
{
"query": {
"bool": {
"filter": {//在filter元素下指定的查询对得分没有影响 - 得分返回为0
"term": {
"status": "active"
}
}
}
}
}
GET _search
{
"query": {
"bool": {
"must": {//有一个match_all查询,它为所有文档指定1.0分
"match_all": {}
},
"filter": {
"term": {
"status": "active"
}
}
}
}
}
![]()
![]() 3.6.3 disjunction Max查询
3.6.3 disjunction Max查询
Dis Max Query,映射到Lucene DisjunctionMaxQuery,本质多域联合搜索,并且不同域指定不同的权重,命中时取最大得分域结果作为结果得分。与直接多域boost求和是完全不同的结果。
![]()
![]() 3.6.4 function score查询
3.6.4 function score查询
Function Score Query,function_score允许您修改查询检索的文档的分数
GET /_search
{
"query": {
"function_score": {
"query": { "match_all": {} },
"boost": "5",
"random_score": {},
"boost_mode":"multiply"
}
}
}
![]()
![]() 3.7 父子文档查询
3.7 父子文档查询
Joining queries,在像ES这样的分布式系统中执行完整的SQL样式连接非常昂贵。相反,Elasticsearch提供两种形式的连接,旨在水平扩展。
nested query | 文档可能包含 nested类型的字段。这些字段用于索引对象数组,其中每个对象都可以作为独立文档查询(使用嵌套查询)。 |
has_child and has_parent | 单个索引中的文档之间可以存在 join field relationship。has_child查询返回其子文档与指定查询匹配的父文档,而has_parent查询返回其父文档与指定查询匹配的子文档。 |
![]()
![]() 3.8 Geo查询
3.8 Geo查询
Geo queries,Elasticsearch支持两种类型的地理数据:支持纬度/经度对的geo_point字段和支持点,线,圆,多边形,多边形等的geo_shape字段。
geo_shape query | 查找具有地理形状的文档,这些地理形状要么与指定的地理形状相交,要么包含,要么不与指定的地理形状相交。 |
geo_bounding_box query | 查找具有落入指定矩形的地理点的文档。 |
geo_distance query | 查找具有指定中心点距离内的地理点的文档。 |
geo_polygon query | 在指定的多边形内查找包含地理点的文档。 |
![]()
![]() 3.9 特殊查询
3.9 特殊查询
Specialized queries,包含其他特殊的查询
more_like_this query | 查找与指定的文本,文档或文档集类似的文档。 |
script query | 允许脚本充当过滤器。另请参阅function_score查询。 |
percolate query | 查找存储为与指定文档匹配的文档的查询。 |
wrapper query | 以json或yaml字符串接受其他查询的查询。 |
![]()
![]() 3.10 Span查询
3.10 Span查询
Span queries,跨度查询是低级位置查询,可以对指定词的顺序和接近度进行专家控制。这些通常用于对法律文件或专利实施非常具体的查询。适用场景小众,不做展开。
总结,本文主要是对Search API和Query DSL做了详细讲解,下一节讲重点讲解查询方面的聚合操作。


最新评论: