平时使用redis时候我们要从redis数据中查找key或者查找带特定前缀后缀的key列表手动处理数据。
如果有成千上万个key呢。
输入keys * 然后 cmd窗口一直在刷数据,一直刷…
keys
redis 提供了一个简单暴力的指令 keys 用来列出所有满足特定正则字符串规则的 key。

假设这是几百万个数据
现在我们使用keys * 可想而知会一直刷数据,占用资源,严重造成服务器崩溃。
keys 正则
可以使用keys 正则 来查询数据
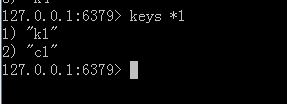
但无法返回指定数据数量,海量数据中运气好会查到你想要的数据,运气不好还是会一直刷数据。
明显有两个缺点
1 没有 offset、limit 参数,一次性吐出所有满足条件的 key。
2 keys 算法是遍历算法,复杂度是 O(n) 数据量大时可能会造成服务器卡顿等。
Redis 为了解决这个问题,在2.8版本后为我们提供了一个带返回结果的最大条数和正则的查看命令 scan
scan
scan 参数提供了三个参数
第一个是 cursor 整数值
第二个是 key 的正则模式
第三个是遍历的 limit hint。
第一次遍历时,cursor 值为 0,然后将返回结果中第一个整数值作为下一次遍历的 cursor。一直遍历到返回的 cursor 值为 0 时结束。
可以如下图所示
数据库里有8条数据,我们来使用scan查出k开头的key,如下所有k开头的数据。
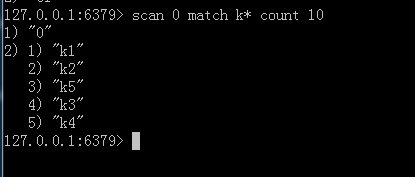
现在查看k开头的数据 每次返回1(大概)条 。( limit 不是限定返回结果的数量,而是限定服务器单次遍历的字典槽位数量(约等于) )
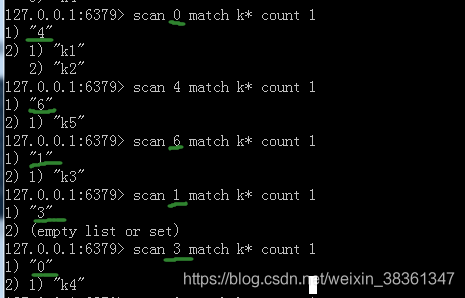
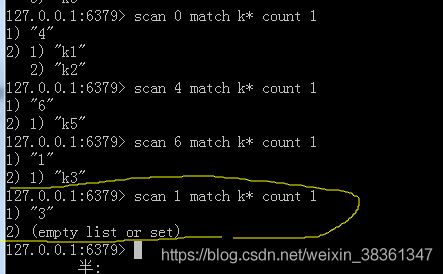
可以看到刚开始 查询时 cursor 是 0 表示第一次查询 , 要求返回1条数据,返回2条(这个结果是大概返回近似于要求返回的结果条数)
返回的游标值不为零 ,图中的绿色线标注的返回的第一行的数值结果 是4, 然后接着下一次查询 按照这次返回的游标继续查询,直到游标是0 表示返回结果完毕。
大白话就是返回的游标不是0就表示遍历没结束,只是拿到了返回的一定数量值(这里可以理解为分页,多少页的数据),然后下次遍历查询,根据上次返回的游标值作为开始查询的游标值再进行查询(可以理解为上次已经查询过了的多少页,继续往下查下一页数据。)
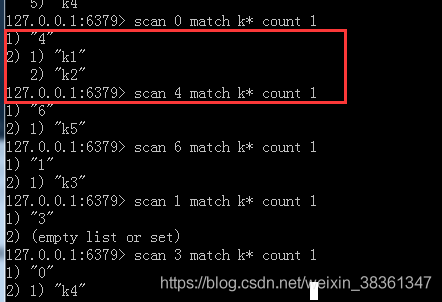
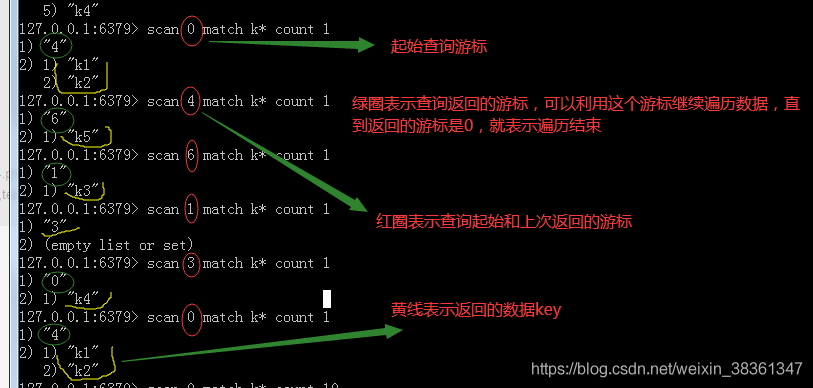
图中返回的位空数据,遍历到这块儿的时候,槽为是空的,没有数据。
其他指令
scan 指令是一系列指令,除了可以遍历所有的 key 之外,还可以对指定的容器集合进行遍历。
比如
zscan 遍历 zset 集合元素
hscan 遍历 hash 字典的元素
sscan 遍历 set 集合的元素
原文链接:https://blog.csdn.net/weixin_38361347/article/details/104742263


最新评论: