本文主要讲述ElasticSearch5.6.1如何监控集群状态、查看集群信息的一般操作方法。
关于ElasticSearch5.6.1的环境搭建,请参考我另一篇博文。
http://blog.csdn.net/deliciousion/article/details/78055724
在使用ES的过程中,我们时常要关注着集群的状态。
ES查看集群的状态实际上也是使用RESTful的接口,而且一般用的是GET方法,所以本文演示就直接用浏览器演示就好了。
curl和kibana下Dev tools的console方法都是一样的。
crul
curl -X get [请求的链接]
kibana
GET [请求的链接]
也许,我们查看集群状态频率最高的是下面这个。
http://[主机IP]:[ES端口]
通常我们启动服务器之后,就可以通过这个简单的方式来验证服务器是否启动成功。
从下面返加的JSON我们可以得到该节点的节点名,所属集群名,ES版本号,lucene版本号。
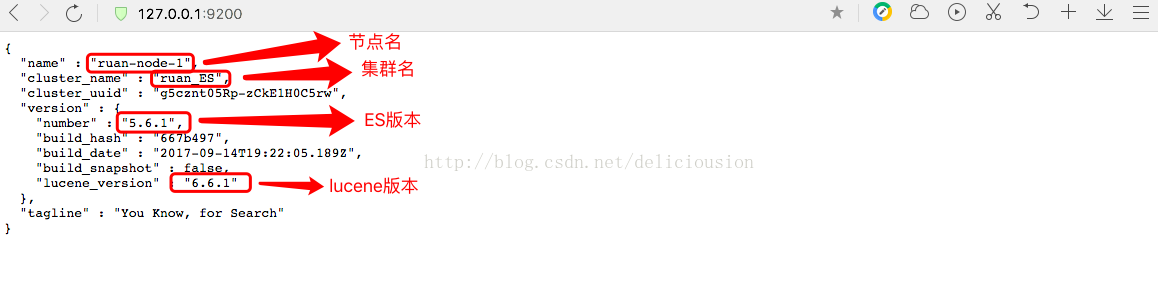
本次演示的集群有两个节点,属于本地单台机器的两个节点。
主机IP和端口如下
127.0.0.1:9200
127.0.0.1:9201
所以我们从另外一个节点进入,情况是一样的。

因此在下面演示过程中,端口号使用9200与9201无异,我选择9200端口进行演示。
下面演示利用其它URL来监控和查看集群状态。
1.查看集群的健康状态。
http://127.0.0.1:9200/_cat/health?v
URL中_cat表示查看信息,health表明返回的信息为集群健康信息,?v表示返回的信息加上头信息,跟返回JSON信息加上?pretty同理,就是为了获得更直观的信息,当然,你也可以不加,不要头信息,特别是通过代码获取返回信息进行解释,头信息有时候不需要,写shell脚本也一样,经常要去除一些多余的信息。
通过这个链接会返回下面的信息,下面的信息包括:
集群的状态(status):red红表示集群不可用,有故障。yellow黄表示集群不可靠但可用,一般单节点时就是此状态。green正常状态,表示集群一切正常。
节点数(node.total):节点数,这里是2,表示该集群有两个节点。
数据节点数(node.data):存储数据的节点数,这里是2。数据节点在Elasticsearch概念介绍有。
分片数(shards):这是12,表示我们把数据分成多少块存储。
主分片数(pri):primary shards,这里是6,实际上是分片数的两倍,因为有一个副本,如果有两个副本,这里的数量应该是分片数的三倍,这个会跟后面的索引分片数对应起来,这里只是个总数。
激活的分片百分比(active_shards_percent):这里可以理解为加载的数据分片数,只有加载所有的分片数,集群才算正常启动,在启动的过程中,如果我们不断刷新这个页面,我们会发现这个百分比会不断加大。
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent1506327257 16:14:17 ruan_ES green 2 2 12 6 0 0 0 0 - 100.0%

2.查看集群的索引数。
http://127.0.0.1:9200/_cat/indices?v
通过该连接返回了集群中的所有索引,其中.kibana是kibana连接后在es建的索引,school是我自己添加的。
这些信息,包括
索引健康(health),green为正常,yellow表示索引不可靠(单节点),red索引不可用。与集群健康状态一致。
状态(status),表明索引是否打开。
索引名称(index),这里有.kibana和school。
uuid,索引内部随机分配的名称,表示唯一标识这个索引。
主分片(pri),.kibana为1,school为5,加起来主分片数为6,这个就是集群的主分片数。
文档数(docs.count),school在之前的演示添加了两条记录,所以这里的文档数为2。
已删除文档数(docs.deleted),这里统计了被删除文档的数量。
索引存储的总容量(store.size),这里school索引的总容量为6.4kb,是主分片总容量的两倍,因为存在一个副本。
主分片的总容量(pri.store.size),这里school的主分片容量是7kb,是索引总容量的一半。
health status index uuid pri rep docs.count docs.deleted store.size pri.store.sizegreen open .kibana fOZj7Gw4TcCh2J-NqqN7kw 1 1 1 0 6.4kb 3.2kbgreen open school 3siCj6cRSHGdP7kvXPWQgw 5 1 2 0 14.1kb 7kb

3.查看集群所在磁盘的分配状况
http://127.0.0.1:9200/_cat/allocation?v
通过该连接返回了集群中的各节点所在磁盘的磁盘状况
返回的信息包括:
分片数(shards),集群中各节点的分片数相同,都是6,总数为12,所以集群的总分片数为12。
索引所占空间(disk.indices),该节点中所有索引在该磁盘所点的空间。
磁盘使用容量(disk.used),已经使用空间41.6gb
磁盘可用容量(disk.avail),可用空间4.3gb
磁盘总容量(disk.total),总共容量45.9gb
磁盘便用率(disk.percent),磁盘使用率90%。
shards disk.indices disk.used disk.avail disk.total disk.percent host ip node6 10.2kb 41.6gb 4.3gb 45.9gb 90 127.0.0.1 127.0.0.1 ruan-node-16 10.2kb 41.6gb 4.3gb 45.9gb 90 127.0.0.1 127.0.0.1 ruan-node-2
4.查看集群的节点
http://127.0.0.1:9200/_cat/nodes?v
通过该连接返回了集群中各节点的情况。这些信息中比较重要的是master列,带*星号表明该节点是主节点。带-表明该节点是从节点。
另外还是heap.percent堆内存使用情况,ram.percent运行内存使用情况,cpu使用情况。
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name127.0.0.1 19 99 6 2.86 mdi * ruan-node-1127.0.0.1 13 99 6 2.86 mdi - ruan-node-2
5.查看集群的其它信息。
http://127.0.0.1:9200/_cat/
通过上面的链接,其实,我们就相当于获得查看集群信息的目录。
=^.^=/_cat/allocation/_cat/shards/_cat/shards/{index}/_cat/master/_cat/nodes/_cat/tasks/_cat/indices/_cat/indices/{index}/_cat/segments/_cat/segments/{index}/_cat/count/_cat/count/{index}/_cat/recovery/_cat/recovery/{index}/_cat/health/_cat/pending_tasks/_cat/aliases/_cat/aliases/{alias}/_cat/thread_pool/_cat/thread_pool/{thread_pools}/_cat/plugins/_cat/fielddata/_cat/fielddata/{fields}/_cat/nodeattrs/_cat/repositories/_cat/snapshots/{repository}/_cat/templates
其实很多都可以见词知义的,希望读者们把上面都尝试一遍,很多东西,特别是ES的一些基本概念就懂了。
有关集群信息的查看就演示到这里,其实我只是演示了很小的一部分,但是根据这些步骤,你们可以继续探索下去了。
如果有什么更好的方法,可以留言告诉我哦,比如一些可视化工具之类的,希望大家一起交流。


最新评论: