
terms聚合
本文概览
1、实战开发遇到聚合问题
请教一个问题,ES 在聚合的时候发生了一个奇怪的现象聚合的语句里面size设置为10和大于10导致聚合的数量不一致,这个size不就是返回的条数吗?会影响统计结果吗?dsl语句摘要(手机敲不方便,双引号就不写了):
aggs:{topcount:{terms:{field:xx,size:10}}}就是这个size,设置10和大于10将会导致聚合结果不一样,难道是es5.x的bug吗?
以上是实战中的真实问题,基于这个问题,有了本篇文章。
本文探讨的聚合主要指:terms 分桶聚合。下图为分桶 terms 聚合示意图。
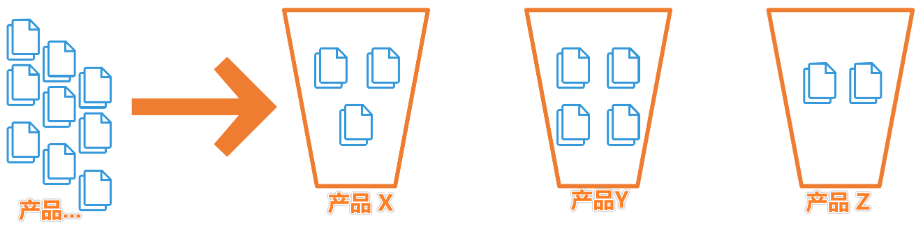
从一堆多分类的产品中聚合出 TOP 3 的产品分类和数量。TOP3 结果:
产品 Y:4 产品 X:3 产品 Z:2
2、前提认知:Elasticsearch terms 分桶聚合结果是不精确的
2.1 Elasticsearch 分片 和 副本
Elasticsearch 索引由一个或多个主分片以及零个或者多个副本分片组成。
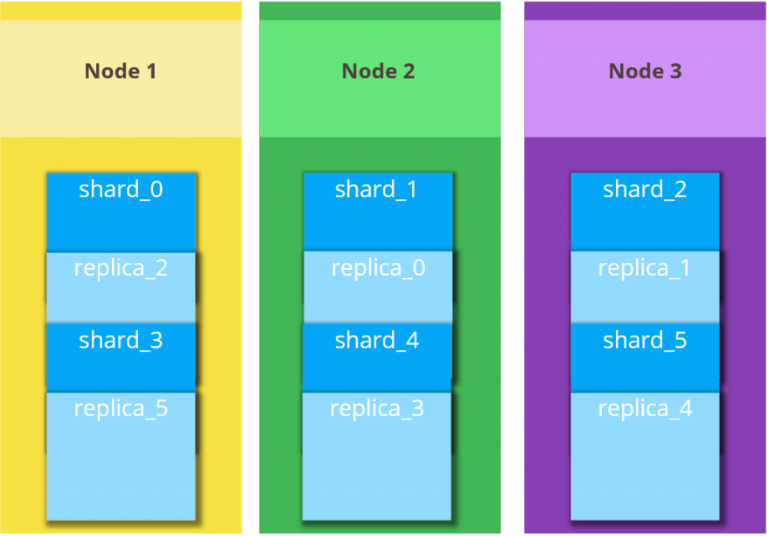
索引的大小超过了单个节点的硬件限制,分片就可以解决。
分片包含索引数据的一个子集,并且本身具有完全的功能和独立性,你可以将分片视为“独立索引”。
分片的核心要义:
分片可以拆分并扩展数据量。
如果数据量不断增加,将会遇到存储瓶颈。举例:有1TB的数据,但只有两个节点(单节点512GB存储)?单独无法存储,切分分片后,问题游刃有余的解决。
操作可以分布在多个节点上,从而可以并行化提高性能。
主分片:写入过程先写主分片,写入成功后再写入副本分片,恢复阶段也以主分片为主。
副本分片的目的:
在节点或分片发生故障时提供高可用性。
副本分片永远不会分配给与主分片相同的节点。
提高搜索查询的性能。
因为可以在所有主、副本上并行执行搜索、聚合操作。
2.2 分片的分配机制
Elasticsearch 如何知道要在哪个分片上存储新文档,以及在通过 ID 检索它时如何找到它?
默认情况下,文档应在节点之间平均分配,这样就不会有一个分片包含的文档比另一个分片多非常多。
确定给定文档应存储在哪个分片的机制称为:路由。
为了使 Elasticsearch 尽可能易于使用,默认情况下会自动处理路由,并且大多数用户不需要手动 reroute 处理它。
Elasticsearch 使用如下图的简单的公式来确定适当的分片。

shard = hash(routing) % total_primary_shards
routing: 文档 id,可以自己指定或者系统生成 UUID。
total_primary_shards:主分片数。
这里推演一道面试题:一旦创建索引后,为什么无法更改索引的主分片数量?
考虑如上路由公式,我们就可以找到答案。
如果我们要更改分片的数量,那么对于文档,运行路由公式的结果将发生变化。
假设:设置有 5 个分片时文档已存储在分片 A 上,因为那是当时路由公式的结果。
后面我们将主分片更改为7个,如果再尝试通过ID查找文档,则路由公式的结果可能会有所不同。
现在,即使文档实际上存储在Shard A上,该公式也可能会路由到ShardB。这意味着永远不会找到该文档。
以此可以得出:主分片创建后不能更改的结论。
较真的同学,看到这里可能会说:不是还有 Split 切分分片和 Shrink 压缩分片机制吗?
毕竟Split 和 Shrink 对分片的处理是有条件的(如:都需要先将分片设置为只读)。
所以,长远角度还是建议:提前根据容量规模和增量规模规划好主分片个数。
2.3 Elasticsearch 如何检索 / 聚合数据?
接收客户端请求的节点为:协调节点。如下图中的节点 1 。
在协调节点,搜索任务被分解成两个阶段:query 和 fetch 。
真正搜索或者聚合任务的节点称为:数据节点。如下图中的:节点 2、3、4。
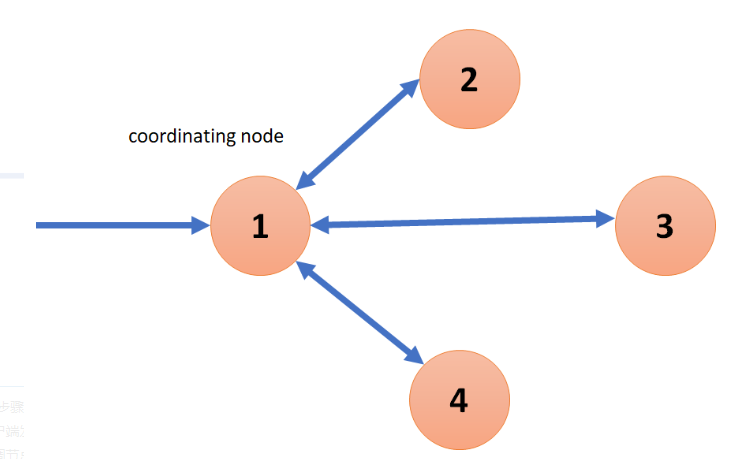
聚合步骤:
客户端发送请求到协调节点。
协调节点将请求推送到各数据节点。
各数据节点指定分片参与数据汇集工作。
协调节点进行总结果汇集。
2.4 示例说明 聚合结果不精确
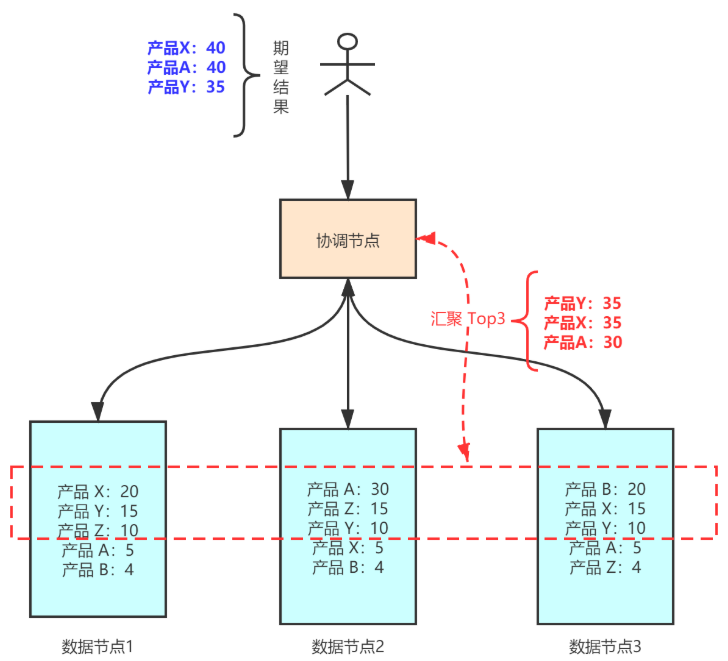
集群:3个节点,3个主分片,每个分片有5个产品的数据。用户期望返回Top 3结果如下:
产品X:40 产品A:40 产品Y:35
用户执行如下 terms 聚合,期望返回集群 prodcuts 索引Top3 结果。
POST products/_search
{
"size":0,
"aggs": {
"product_aggs": {
"terms": {
"field":"name.keyword",
"size":3
}
}
}
}实际执行如下图所示:各节点的分片:取自己的Top3 返回给协调节点。协调节点汇集后结果为:
产品Y:35, 产品X: 35, 产品A:30。
这就产生了实际聚合结果和预期聚合结果不一致,也就是聚合结果不精确。
导致聚合不精确的原因分析:
效率因素:每个分片的取值Top X,并不是汇总全部的 TOP X。
性能因素:ES 可以不每个分片Top X,而是全量聚合,但势必这会有很大的性能问题。
3、如何提高聚合精确度?
思考题——terms 聚合中的 size 和 shard_size 有什么区别?
size:是聚合结果的返回值,客户期望返回聚合排名前三,size值就是 3。
shard_size: 每个分片上聚合的数据条数。shard_size 原则上要大于等于 size(若设置小于size,实则没有意义,elasticsearch 会默认置为size)
请求的size值越高,结果将越准确,但计算最终结果的成本也将越高。
那到底如何提供聚合精准度呢?这里提供了四种方案供参考:
方案1:设置主分片为1
注意7.x版本已经默认为1。
适用场景:数据量小小集群规模业务场景。
方案2:调大 shard_size 值
设置 shard_size 为比较大的值,官方推荐:size*1.5+10
适用场景:数据量大、分片数多的集群业务场景。
shard_size 值越大,结果越趋近于精准聚合结果值。
此外,还可以通过show_term_doc_count_error参数显示最差情况下的错误值,用于辅助确定 shard_size 大小。
方案3:将size设置为全量值,来解决精度问题
将size设置为2的32次方减去1也就是分片支持的最大值,来解决精度问题。
原因:1.x版本,size等于 0 代表全部,高版本取消 0 值,所以设置了最大值(大于业务的全量值)。
全量带来的弊端就是:如果分片数据量极大,这样做会耗费巨大的CPU 资源来排序,而且可能会阻塞网络。
适用场景:对聚合精准度要求极高的业务场景,由于性能问题,不推荐使用。
方案4:使用Clickhouse 进行精准聚合
在星球微信群里,张超大佬指出:分析系统里跑全量的 group by 我觉得是合理的需求, clickhouse很擅长做这种事,es如果不在这方面加强,分析场景很多会被 clickhouse替掉。
腾讯大佬指出:聚合这块比较看场景。因为我这边有一些业务是做聚合,也就是 olap 场景,多维分析,ES并不是特别擅长。如果有丰富的多维分析场景,还有比较高的性能要求。我建议可以调研下clickhouse。我们这边测评过开源和内部的 大部分场景 clickhouse 几十亿的级别,基本也在秒级返回甚至毫秒级。
此外,除了 chlickhouse, spark也有类似聚合的功能。
适用场景:数据量非常大、聚合精度要求高、响应速度快的业务场景。
4、小结
回到开头提到的问题,设置10和大于10将会导致聚合结果不一样是由于 Elasticsearch 聚合实现机制决定的,不是Bug。Elasticsearch本身不提供精准分桶聚合。要提高聚合精度,参考文章提到的几种方案。
大家有更好的精度提升方案,欢迎留言交流。


最新评论: