什么是Elasticsearch?

Elasticsearch是一个开源的分布式、RESTful 风格的搜索和数据分析引擎,它的底层是开源库Apache Lucene。
Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库——无论是开源还是私有,但它也仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。 更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理,因为Lucene 非常复杂。
为了解决Lucene使用时的繁复性,于是Elasticsearch便应运而生。它使用 Java 编写,内部采用 Lucene 做索引与搜索,但是它的目标是使全文检索变得更简单,简单来说,就是对Lucene 做了一层封装,它提供了一套简单一致的 RESTful API 来帮助我们实现存储和检索。
当然,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确地形容:
一个分布式的实时文档存储,每个字段可以被索引与搜索;
一个分布式实时分析搜索引擎;
能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据。
由于Elasticsearch的功能强大和使用简单,维基百科、卫报、Stack Overflow、GitHub等都纷纷采用它来做搜索。现在,Elasticsearch已成为全文搜索领域的主流软件之一。
下面将介绍Elasticsearch的安装与简单使用。
安装并运行Elasticsearch
安装 Elasticsearch 之前,你需要先安装一个较新版本的 Java,最好的选择是,你可以从 www.java.com 获得官方提供的最新版本的Java。
你可以从 elastic 的官网 elastic.co/downloads/elasticsearch 获取最新版本的Elasticsearch。解压文档后,按照下面的操作,即可在前台(foregroud)启动 Elasticsearch:
cd elasticsearch-<version> ./bin/elasticsearch
此时,Elasticsearch运行在本地的9200端口,在浏览器中输入网址“http://localhost:9200/”,如果看到以下信息就说明你的电脑已成功安装Elasticsearch:
{
"name" : "YTK8L4q",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "hB2CZPlvSJavhJxx85fUqQ",
"version" : {
"number" : "6.5.4",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "d2ef93d",
"build_date" : "2018-12-17T21:17:40.758843Z",
"build_snapshot" : false,
"lucene_version" : "7.5.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}在这里,我们安装的Elasticsearch版本号为6.5.4。
Kibana 是一个开源的分析和可视化平台,旨在与 Elasticsearch 合作。Kibana 提供搜索、查看和与存储在 Elasticsearch 索引中的数据进行交互的功能。开发者或运维人员可以轻松地执行高级数据分析,并在各种图表、表格和地图中可视化数据。
你可以从 elastic 的官网 https://www.elastic.co/downloads/kibana 获取最新版本的Kibana。解压文档后,按照下面的操作,即可在前台(foregroud)启动Kibana:
cd kibana-<version> ./bin/kabana
此时,Kibana运行在本地的5601端口,在浏览器中输入网址“http://localhost:5601”,即可看到以下界面:

Kibana启动界面
下面,让我们来了解Elasticsearch的一些基本概念,这有助于我们更好地理解和使用Elasticsearch。
Elasticsearch基本概念
全文搜索(Full-text Search)
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。
在全文搜索的世界中,存在着几个庞大的帝国,也就是主流工具,主要有:
Apache Lucene
Elasticsearch
Solr
Ferret
倒排索引(Inverted Index)
该索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。Elasticsearch能够实现快速、高效的搜索功能,正是基于倒排索引原理。
节点 & 集群(Node & Cluster)
Elasticsearch 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个Elasticsearch实例。单个Elasticsearch实例称为一个节点(Node),一组节点构成一个集群(Cluster)。
索引(Index)
Elasticsearch 数据管理的顶层单位就叫做 Index(索引),相当于关系型数据库里的数据库的概念。另外,每个Index的名字必须是小写。
文档(Document)
Index里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。Document 使用 JSON 格式表示。同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
类型(Type)
Document 可以分组,比如employee这个 Index 里面,可以按部门分组,也可以按职级分组。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document,类似关系型数据库中的数据表。
不同的 Type 应该有相似的结构(Schema),性质完全不同的数据(比如 products 和 logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。
文档元数据(Document metadata)
文档元数据为_index, _type, _id, 这三者可以唯一表示一个文档,_index表示文档在哪存放,_type表示文档的对象类别,_id为文档的唯一标识。
字段(Fields)
每个Document都类似一个JSON结构,它包含了许多字段,每个字段都有其对应的值,多个字段组成了一个 Document,可以类比关系型数据库数据表中的字段。
在 Elasticsearch 中,文档(Document)归属于一种类型(Type),而这些类型存在于索引(Index)中,下图展示了Elasticsearch与传统关系型数据库的类比:

Elasticsearch入门
Elasticsearch提供了多种交互使用方式,包括Java API和RESTful API ,本文主要介绍RESTful API 。所有其他语言可以使用RESTful API 通过端口 9200 和 Elasticsearch 进行通信,你可以用你最喜爱的 web 客户端访问 Elasticsearch 。甚至,你还可以使用 curl 命令来和 Elasticsearch 交互。
一个Elasticsearch请求和任何 HTTP 请求一样,都由若干相同的部件组成:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
返回的数据格式为JSON,因为Elasticsearch中的文档以JSON格式储存。其中,被 < > 标记的部件:
| 部件 | 说明 |
|---|---|
| VERB | 适当的 HTTP 方法 或 谓词 : GET、 POST、 PUT、 HEAD 或者 DELETE。 |
| PROTOCOL | http 或者 https(如果你在 Elasticsearch 前面有一个 https 代理) |
| HOST | Elasticsearch 集群中任意节点的主机名,或者用 localhost 代表本地机器上的节点。 |
| PORT | 运行 Elasticsearch HTTP 服务的端口号,默认是 9200 。 |
| PATH | API 的终端路径(例如 _count 将返回集群中文档数量)。Path 可能包含多个组件,例如:_cluster/stats 和 _nodes/stats/jvm 。 |
| QUERY_STRING | 任意可选的查询字符串参数 (例如 ?pretty 将格式化地输出 JSON 返回值,使其更容易阅读) |
| BODY | 一个 JSON 格式的请求体 (如果请求需要的话) |
对于HTTP方法,它们的具体作用为:
| HTTP方法 | 说明 |
|---|---|
| GET | 获取请求对象的当前状态 |
| POST | 改变对象的当前状态 |
| PUT | 创建一个对象 |
| DELETE | 销毁对象 |
| HEAD | 请求获取对象的基础信息 |
我们以下面的数据为例,来展示Elasticsearch的用法。

以下全部的操作都在Kibana中完成,创建的index为conference, type为event .
插入数据
首先创建index为conference, 创建type为event, 插入id为1的第一条数据,只需运行下面命令就行:
PUT /conference/event/1
{
"host": "Dave",
"title": "Elasticsearch at Rangespan and Exonar",
"description": "Representatives from Rangespan and Exonar will come and discuss how they use Elasticsearch",
"attendees": ["Dave", "Andrew", "David", "Clint"],
"date": "2013-06-24T18:30",
"reviews": 3
}在上面的命令中,路径/conference/event/1表示文档的index为conference, type为event, id为1. 类似于上面的操作,依次插入剩余的4条数据,完成插入后,查看数据如下:
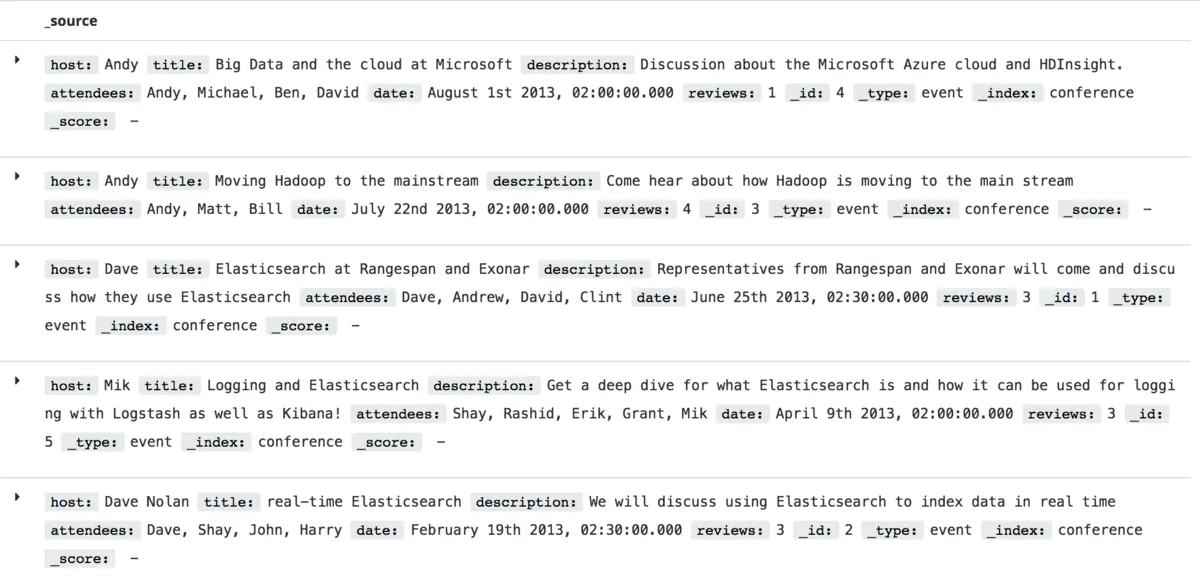
插入数据
删除数据
比如我们想要删除conference中event里面id为5的数据,只需运行下面命令即可:
DELETE /conference/event/5
返回结果如下:
{
"_index" : "conference",
"_type" : "event",
"_id" : "5",
"_version" : 2,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}表示该文档已成功删除。如果想删除整个event类型,可输入命令:
DELETE /conference/event
如果想删除整个conference索引,可输入命令:
DELETE /conference
修改数据
修改数据的命令为POST, 比如我们想要将conference中event里面id为4的文档的作者改为Bob,那么需要运行命令如下:
POST /conference/event/4/_update
{
"doc": {"host": "Bob"}
}返回的信息如下:(表示修改数据成功)
{
"_index" : "conference",
"_type" : "event",
"_id" : "4",
"_version" : 7,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 7,
"_primary_term" : 1
}查看修改后的数据如下:

修改数据
查询数据
查询数据的命令为GET,查询命令也是Elasticsearch最为重要的功能之一。比如我们想查询conference中event里面id为1的数据,运行命令如下:
GET /conference/event/1
返回的结果如下:
{
"_index" : "conference",
"_type" : "event",
"_id" : "1",
"_version" : 2,
"found" : true,
"_source" : {
"host" : "Dave",
"title" : "Elasticsearch at Rangespan and Exonar",
"description" : "Representatives from Rangespan and Exonar will come and discuss how they use Elasticsearch",
"attendees" : [
"Dave",
"Andrew",
"David",
"Clint"
],
"date" : "2013-06-24T18:30",
"reviews" : 3
}
}在_source 属性中,内容是原始的 JSON 文档,还包含有其它属性,比如_index, _type, _id, _found等。
如果想要搜索conference中event里面所有的文档,运行命令如下:
GET /conference/event/_search
返回结果包括了所有四个文档,放在数组 hits 中。
当然,Elasticsearch 提供更加丰富灵活的查询语言叫做 查询表达式 , 它支持构建更加复杂和健壮的查询。利用查询表达式,我们可以检索出conference中event里面所有host为Bob的文档,命令如下:
GET /conference/event/_search
{
"query" : {
"match" : {
"host" : "Bob"
}
}
}返回的结果只包括了一个文档,放在数组 hits 中。
接着,让我们尝试稍微高级点儿的全文搜索——一项传统数据库确实很难搞定的任务。搜索下所有description中含有"use Elasticsearch"的event:
GET /conference/event/_search
{
"query" : {
"match" : {
"description" : "use Elasticsearch"
}
}
}返回的结果(部分)如下:
{
...
"hits" : {
"total" : 2,
"max_score" : 0.65109104,
"hits" : [
{
...
"_score" : 0.65109104,
"_source" : {
"host" : "Dave Nolan",
"title" : "real-time Elasticsearch",
"description" : "We will discuss using Elasticsearch to index data in real time",
...
}
},
{
...
"_score" : 0.5753642,
"_source" : {
"host" : "Dave",
"title" : "Elasticsearch at Rangespan and Exonar",
"description" : "Representatives from Rangespan and Exonar will come and discuss how they use Elasticsearch",
...
}
}
]
}
}返回的结果包含了两个文档,放在数组 hits 中。让我们对这个结果做一些分析,第一个文档的description里面含有“using Elasticsearch”,这个能匹配“use Elasticsearch”是因为Elasticsearch含有内置的词干提取算法,之后两个文档按_score进行排序,_score字段表示文档的相似度(默认的相似度算法为BM25)。
如果想搜索下所有description中严格含有"use Elasticsearch"这个短语的event,可以使用下面的命令:
GET /conference/event/_search
{
"query" : {
"match_phrase": {
"description" : "use Elasticsearch"
}
}
}这时候返回的结果只有一个文档,就是上面输出的第二个文档。
当然,Elasticsearch还支持更多的搜索功能,比如过滤器,高亮搜索,结构化搜索等,希望接下来能有更多的时间和经历来介绍~
总结
后续有机会再介绍如何利用Python来操作Elasticsearch~
本次分享到此结束,感谢大家阅读~
作者:山阴少年
链接:https://www.jianshu.com/p/d48c32423789


最新评论: