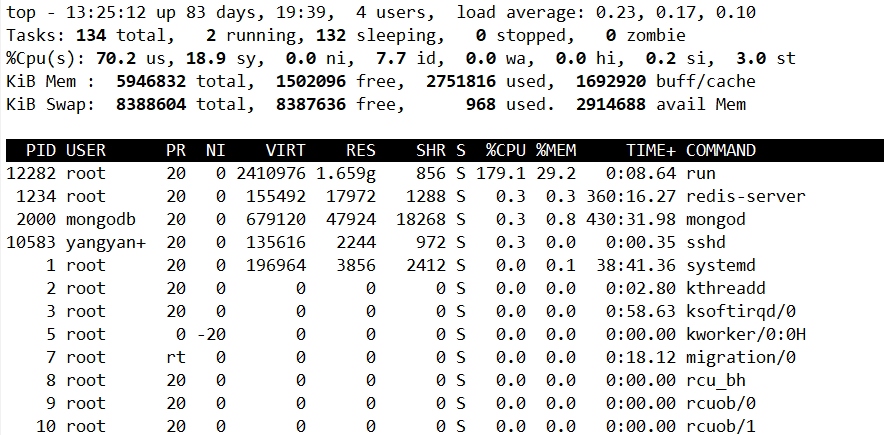
相信大家在学习Go的过程中,都会看到类似这样一句话:"与传统的系统级线程和进程相比,协程的最大优势在于其‘轻量级’,可以轻松创建上百万个而不会导致系统资源衰竭"。那是不是意味着我们在开发过程中,可以随心所欲的调用协程,而不关心它的数量呢?
答案当然是否定的。我们在开发过程中,如果不对Goroutine加以控制而进行滥用的话,可能会导致服务程序整体崩溃。
这里我先模拟一下协程数量太多的危害:
func main() {
number := math.MaxInt64
for i := 0; i < number; i++ {
go func(i int) {
// 做一些业务逻辑处理
fmt.Printf("go func: %d\n", i)
time.Sleep(time.Second)
}(i)
}
}如果number是用户输入的一个参数,没有做限制。有些开发人员会全部丢进去进行循环,认为全部都并发使用Goroutine去做一件事情,效率比较高。但这样的话,噩梦般的事情就开始了,服务器系统资源利用率不断上涨,到最后程序自动killed。
通过执行top命令查看到该程序占用的CPU、内存较高。
为了避免上图这种情况,下面会简单的介绍一下Goroutine以及在我们日常开发中如何控制Goroutine的数量。
一、基本介绍
工欲善其事必先利其器。先简单的介绍一下Goroutine,Goroutine是Go中最基本的执行单元。事实上每一个Go程序至少有一个Goroutine:主Goroutine。当程序启动时,它会自动创建。
为了更好理解Goroutine,先讲一下进程、线程和协程的概念。
进程(process):用户下达运行程序的命令后,就会产生进程。同一程序可产生多个进程(一对多关系),以允许同时有多位用户运行同一程序,却不会相冲突。进程需要一些资源才能完成工作,如CPU使用时间、存储器、文件以及I/O设备,且为依序逐一进行,也就是每个CPU核心任何时间内仅能运行一项进程。进程的局限是创建、撤销和切换的开销比较大。
线程(Thread):有时被称为轻量级进程(Lightweight Process,LWP),是程序执行流的最小单元。一个标准的线程由线程ID,当前指令指针(PC),寄存器集合和堆栈组成。另外,线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。线程拥有自己独立的栈和共享的堆,共享堆,不共享栈,线程的切换一般也由操作系统调度。
协程(coroutine):又称微线程与子例程(或者称为函数)一样,协程(coroutine)也是一种程序组件。相对子例程而言,协程更为一般和灵活,但在实践中使用没有子例程那样广泛。和线程类似,共享堆,不共享栈,协程的切换一般由程序员在代码中显式控制。它避免了上下文切换的额外耗费,兼顾了多线程的优点,简化了高并发程序的复杂。
Goroutine和其他语言的协程(coroutine)在使用方式上类似,但从字面意义上来看不同(一个是Goroutine,一个是coroutine),再就是协程是一种协作任务控制机制,在最简单的意义上,协程不是并发的,而Goroutine支持并发的。因此Goroutine可以理解为一种Go语言的协程,同时它可以运行在一个或多个线程上。
在Go中生成一个Goroutine的方式非常的简单:只要在函数前面加上go就生成了。
func number() {
for i := 0; i < ; i++ {
fmt.Printf("%d ", i)
}
}
func main() {
go number() // 启动一个goroutine
number()
}二、协程池解决?
回到开头的问题,如何控制Goroutine的数量?相信有过开发经验的人,第一想法是生成协程池,通过协程池控制连接的数量,这样每次连接都从协程池里去拿。在Golang开发中需要协程池吗?这里分享下知乎有个相关点赞最高的回答:
显然不需要,goroutine的初衷就是轻量级的线程,为的就是让你随用随起,结果你又搞个池子来,这不是脱裤子放屁么?你需要的是限制并发,而协程池是一种违背了初衷的方法。池化要解决的问题一个是频繁创建的开销,另一个是在等待时占用的资源。goroutine 和普通线程相比,创建和调度都不需要进入内核,也就是创建的开销已经解决了。同时相比系统线程,内存占用也是轻量的。所以池化技术要解决的问题goroutine 都不存在,为什么要创建 goroutine pool 呢?如果因为 goroutine 持有资源而要去创建goroutine pool,那只能说明代码的耦合度较高,应该为这类资源创建一个goroutine-safe的对象池,而不是把goroutine本身池化。
在我们日常大部分场景下,不需要使用协程池。因为Goroutine非常轻量,默认2kb,使用go func()很难成为性能瓶颈。当然一些极端情况下需要追求性能,可以使用协程池实现资源的复用,例如FastHttp使用协程池性能提高许多。
当然现在我们如果需要使用Goroutine池也不需要重复造轮子了,目前github上已经有开源的项目ants来实现 Goroutine 池。ants已经实现了对大规模 Goroutine 的调度管理、Goroutine 复用,允许使用者在开发并发程序的时候限制 Goroutine 数量,复用资源,达到更高效执行任务的效果。
项目地址:https://github.com/panjf2000/ants
三、 通过channel和sync方式限制协程数量
Goroutine运行在相同的地址空间,因此访问共享内存必须做好同步。那么Goroutine之间如何进行数据的通信呢?Go提供了一个很好的通信机制channel,channel可以与 Unix shell 中的双向管道做类比:可以通过它发送或者接收值。这些值只能是特定的类型:channel类型。定义一个channel时,也需要定义发送到channel的值的类型。注意,必须使用make创建channel。
Go语言中有一个sync.WaitGroup,WaitGroup 对象内部有一个计数器,最初从0开始,它有三个方法:Add(), Done(), Wait() 用来控制计数器的数量。下面示例代码中wg.Wait会阻塞代码的运行,直到计数器值为0。
通过Golang自带的channel和sync,可以实现需求,下面代码中通过channel控制Goroutine数量。
package main
import (
"fmt"
"sync"
"time"
)
type Glimit struct {
n int
c chan struct{}
}
// initialization Glimit struct
func New(n int) *Glimit {
return &Glimit{
n: n,
c: make(chan struct{}, n),
}
}
// Run f in a new goroutine but with limit.
func (g *Glimit) Run(f func()) {
g.c <- struct{}{}
go func() {
f()
<-g.c
}()
}
var wg = sync.WaitGroup{}
func main() {
number := 10
g := New(2)
for i := 0; i < number; i++ {
wg.Add(1)
value :=i
goFunc := func() {
// 做一些业务逻辑处理
fmt.Printf("go func: %d\n", value)
time.Sleep(time.Second)
wg.Done()
}
g.Run(goFunc)
}
wg.Wait()
}四、总结
在文章的开头通过在服务器模拟Goroutine数量太多导致系统资源上升,提醒大家避免这类问题。当然每个人可根据自己所在的场景选择最合适的方案,有时候成熟的第三方库也是个很好的选择,可以避免重复造轮子。
下面有两个思考问题,大家可以尝试着去思考一下。
思考1:为什么我们要使用sync.WaitGroup?
这里如果我们不使用sync.WaitGroup控制的话,原因出在当主程序结束时,子协程也是会被终止掉的。因此剩余的 goroutine 没来及把值输出,程序就已经中断了
思考2:代码中channel数据结构为什么定义struct,而不定义成bool这种类型呢?
因为空结构体变量的内存占用大小为0,而bool类型内存占用大小为1,这样可以更加最大化利用我们服务器的内存空间。
func main(){
a :=struct{}{}
b := true
fmt.Println(unsafe.Sizeof(a)) # println 0
fmt.Println(unsafe.Sizeof(b)) # println 1
}https://mp.weixin.qq.com/s/EPiVoDXQGn8jtSzmSOKGeg


最新评论: