1.实现目标
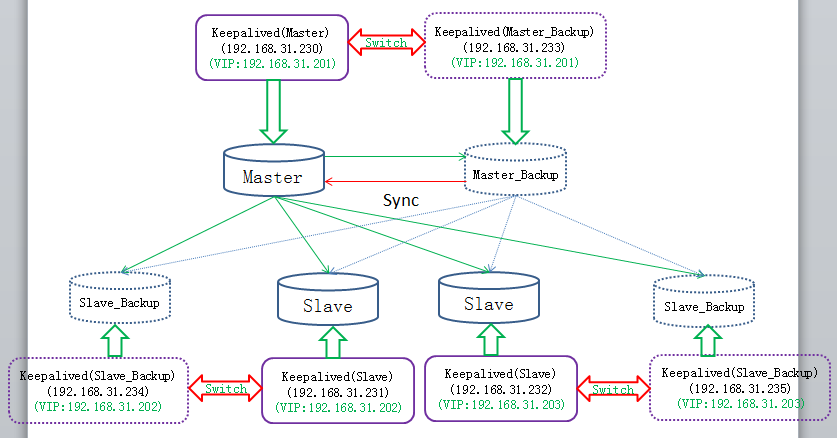
目标清单:
1)Master(192.168.31.230)为正常运行环境下的主库,为两个Slave(192.168.31.231和192.168.31.232)提供“主-从”复制功能;
2)Master_Backup(192.168.31.233)是Master的备份库,只要Master是正常的,它不对外提供服务。它与Master之间属于"主-主"复制关系,即自己既是主机,又是对方的从机;
3)同理,192.168.31.234和192.168.31.235为Slave_Backup,分别为192.168.31.231和 192.168.31.232的备份库,只要Slave是正常的,对应的备份机不对外提供服务;
4)Slave在此架构中的目的是为了实现读写分离,对应用程序来说,Master只负责写,两个Slave只负责读。Slave的数据来源于Master的复制操作;
5)如果Master由于某种原因(例如:宕机和断电等)导致不能正常运行,则此时需要让Master_Backup自动切换为新主机,而Slave和Slave_Backup也能自动切换数据源到Master_Backup;
6)同理,如果Slave由于某种原因(例如:宕机和断电等)导致不能正常运行,则此时需要让对应的Slave_Backup自动切换为新从机;
7)无论是Master还是切换后的Master_Backup,它们向客户端提供的连接地址应保持一致,如上图提供的VIP+Port,即192.168.31.201:3306,Slave和Slave_Backup也应如此,对外提供的连接地址始终是192.168.31.202:3306和192.168.31.203:3306。
2.实现过程
MySQL安装步骤不在此讲述。
2.1实现Master-Master结构
2.1.1修改Master和Master_Backup配置文件,vi /etc/my.cnf
主要在[mysqld]内添加如下配置项:
Sql配置代码:
# log文件名,必填 log-bin = mysql-bin # 服务器Id,必须唯一 server-id = 230 # 不参与同步的数据库名,有多个则添加多个配置项 binlog-ignore-db = mysql # Master-Master结构必须的 log-slave-updates slave-skip-errors = all sync_binlog = 1 read_only = 0
2.1.2为复制请求方提供链接账号和密码
由于是Master-Master结构,因此需在双方终端中执行如下SQL命令:
Sql代码:
GRANT REPLICATION SLAVE ON *.* to 'slave'@'%' identified by 'slave123';
可在mysql实例的user表中查询到记录,重点关注Repl_slave_priv字段的值是否为Y,此账号(用户名:slave,密码:slave123)主要用于定位复制点
2.1.3在从机上指定Master数据源
1)在Master上执行
Sql代码:
SHOW MASTER STATUS;
得到的结果如下:
重点关注File和Position两个字段值
2)在Master_Backup也执行上述步骤,由于是初始状态,得到的结果和上图一样;
3)在Master上执行如下SQL命令,填入Master_Backup的host、链接账号和密码、File和Position值
Sql代码:
SLAVE STOP; CHANGE MASTER TO MASTER_HOST='192.168.31.233',MASTER_USER='slave',MASTER_PASSWORD='slave123',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=107; SLAVE START;
4)在Master_Backup上执行如下SQL命令,填入Master的host、链接账号和密码、File和Position值
Sql代码:
SLAVE STOP; CHANGE MASTER TO MASTER_HOST='192.168.31.230',MASTER_USER='slave',MASTER_PASSWORD='slave123',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=107; SLAVE START;
5)重启Master和Master_Backup
2.1.4测试
1)当Master和Master_Backup都正常运行时,在任意一端更新数据后都会同步到另一段;
2)当Master处于不可运行时,在Master_Backup更新数据后重启Master,这时在Master上可得到最新的数据;
3)当Master_Backup处于不可运行时,在Maste更新数据后重启Master_Backup,这时在Master_Backup上可得到最新的数据。
2.2实现Master-Slave结构
2.2.1实施过程
将2.1.1和2.1.3的过程在所有Slave上操作一遍即可,需要注意配置文件中server-id一定要唯一,还有在执行CHANGE MASTER TO命令时,MASTER_HOST为192.168.31.230
Sql代码:
SLAVE STOP; CHANGE MASTER TO MASTER_HOST='192.168.31.230',MASTER_USER='slave',MASTER_PASSWORD='slave123',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=107; SLAVE START;
2.2.2测试
1)当Master和Master_Backup都正常运行时,在任意一端更新数据后都会同步到两个Slave上;
2)当Master处于正常运行时,在此端更新数据后都会同步到两个Slave上,而无论Master_Backup是否正常;
3)当Master处于不可运行时,Master_Backup通过Monitor(Keepalived)成为接管者,在Master_Backup更新数据后都会同步到所有Slave上,并且重启Master后,最新数据也会同步到此端。
可事与愿违,在第3)种场景下,Master_Backup不会将数据同步给Slave,即使后来在Slave上将MASTER_HOST指定为Keepalived提供的VIP(192.168.31.201)也无济于事:
Sql代码:
SLAVE STOP; CHANGE MASTER TO MASTER_HOST='192.168.31.201',MASTER_USER='slave',MASTER_PASSWORD='slave123',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=107; SLAVE START;
在Slave上执行SHOW SLAVE STATUS;
得出如下结果:

究其原因,如上图所示,Master_Server_Id为230,仍然指向的是已经处于不可运行的Master,而预期结果是希望它能自动的更新定位到Master_Backup(233)上,达到自动切换的目的。
没办法,只有自己执行CHANGE MASTER TO...手动定位了。我草...,一不注意就会定位错误,造成数据丢失的问题,而且也不满足快速响应容灾切换的目的。
3.最终方案
最终方案将选择mysql-mmm结合半同步机制来实现容灾自动切换。
3.1在master(230和233)上安装semisync master并设置
Sql代码:
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so'; INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so'; SET GLOBAL rpl_semi_sync_master_enabled = 1; SET GLOBAL rpl_semi_sync_slave_enabled = 1;
vi /ect/my.cnf后加入如下配置:
配置代码:
rpl_semi_sync_master_enabled = 1 rpl_semi_sync_slave_enabled = 1
3.2在slave(231、232、234和235)上安装slave插件并设置
Sql代码:
INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so'; SET GLOBAL rpl_semi_sync_slave_enabled = 1;
vi /ect/my.cnf后加入如下配置:
配置代码
rpl_semi_sync_slave_enabled = 1
3.3所有mysql实例停止slave并开启slave,使半同步机制生效
Sql代码:
stop slave; start slave;
3.4查看semisync状态
Sql代码:
show status like '%emi%';
重点关注:
1)Rpl_semi_sync_master_clients:与当前master建立半同步连接的客户端数;
2)Rpl_semi_sync_master_status:作为半同步master端的就绪状态(ON:就绪,OFF:未就绪)
3)Rpl_semi_sync_slave_status:作为半同步slave端的就绪状态(ON:就绪,OFF:未就绪)
3.5安装mysql-mmm
3.5.1新增一台专门用于监控mysql的服务器(mysql_monitor),IP为192.168.31.250
3.5.2在mysql_monitor、master、master_backup、slave和slave_backup上安装epel网络源
Linux命令行代码:
yum install http://mirrors.hustunique.com/epel//6/x86_64/epel-release-6-8.noarch.rpm
3.5.3在mysql_monitor上安装mysql-mmm-monitor
Linux命令行代码:
yum -y install mysql-mmm-monitor
3.5.4在master、master_backup、slave和slave_backup上安装和配置
1)安装mysql-mmm-agent
Linux命令行代码:
yum -y install mysql-mmm-agent
2)授权monitor访问
Sql代码:
GRANT REPLICATION CLIENT ON *.* TO 'mmm_monitor'@'192.168.31.%' IDENTIFIED BY 'monitor'; GRANT SUPER,REPLICATION CLIENT, PROCESS ON *.* TO 'mmm_agent'@'192.168.31.%' IDENTIFIED BY'agent';
3)编辑mmm_agent.conf配置文件
vi /etc/mysql-mmm/mmm_agent.conf
Mmm_agent.conf配置文件代码:
# 包含公用配置文件 include mmm_common.conf # 对应<code><span style="color: #008000;"><span style="color: #000000;">mmm_common.conf中定义的某个host名称</span></span></code> this db1 # 设置成1时,将打印日志到前台,按ctrl+c将结束进程 debug 0 max_kill_retries 1
4)编辑mmm_common.conf配置文件
vi /etc/mysql-mmm/mmm_common.conf
Mmm_common.conf代码:
active_master_role writer <host default> # 对应当前主机的网络接口名 cluster_interface eth2 pid_path /var/run/mysql-mmm/mmm_agentd.pid bin_path /usr/libexec/mysql-mmm/ mysql_port 3306 agent_port 9989 # 对应GRANT REPLICATION SLAVE ON语句创建的账号和密码 replication_user slave replication_password slave123 # GRANT SUPER,REPLICATION CLIENT, PROCESS ON语句创建的账号和密码 agent_user mmm_agent agent_password agent </host> # master的配置 # 其中host后面的值定义的是某台数据库服务的别名,一般就用服务器的主机名即可 <host db1> ip 192.168.31.230 mode master # db1的master对等点 peer db2 </host> # master_backup的配置 <host db2> ip 192.168.31.233 mode master # db2的master对等点 peer db1 </host> # slave的配置 <host db3> ip 192.168.31.231 mode slave </host> # slave的配置 <host db4> ip 192.168.31.232 mode slave </host> # slave_backup的配置 <host db5> ip 192.168.31.234 mode slave </host> # slave_backup的配置 <host db6> ip 192.168.31.235 mode slave </host> # 定义writer角色,即架构中的master和master_backup # ips为writer对外提供的vip <role writer> hosts db1, db2 ips 192.168.31.201 mode exclusive </role> # 定义reader角色,即架构中的两个slave和两个slave_backup # ips为reader对外提供的vip <role reader> hosts db3, db4, db5, db6 ips 192.168.31.202, 192.168.31.203 mode balanced </role>
注意,需要将此配置文件复制到mysql_monitor的同名目录下
3.5.5在master、master_backup、slave和slave_backup上启动mmm agent服务,并设置为开机服务
执行如下启动命令:
Linux命令行代码:
/etc/init.d/mysql-mmm-agent start
如果出现如下示例信息:

则说明配置成功
vi /etc/rc.d/rc.local后,将上述命令行添加到mysql启动命令的下面
3.5.6编辑mysql_monitor上的配置文件mmm_mon.conf
vi /etc/mysql-mmm/mmm_mon.conf
Mmm-mon.conf代码:
include mmm_common.conf <monitor> # 本机IP ip 192.168.31.250 port 9988 pid_path /var/run/mysql-mmm/mmm_mond.pid bin_path /usr/libexec/mysql-mmm status_path /var/lib/mysql-mmm/mmm_mond.status # 所有MySQL服务器的IP ping_ips 192.168.31.230, 192.168.31.231, 192.168.31.232, 192.168.31.233, 192.168.31.234, 192.168.31.235 auto_set_online 0 </monitor> <host default> # GRANT REPLICATION CLIENT ON语句创建的账号和密码 monitor_user mmm_monitor monitor_password monitor </host> <check mysql> # 每5秒检查一次 check_period 5 trap_period 10 # 检查超时秒数 timeout 2 restart_after 10000 max_backlog 60 </check> <code># 设置为1,开启调试模式,打印日志到前台,ctrl+c将结束进程,对于调试有帮助</code> debug 0
关于mmm_agent.conf、mmm_common.conf、mmm_mon.conf和mmm_mon_log.conf的具体内容,可以参考http://blog.chinaunix.net/uid-16844903-id-3152138.html
3.5.7在上mysql_monitor开启mmm monitor监控,并设置为开机服务
执行如下启动命令:
Linux命令行代码:
/etc/init.d/mysql-mmm-monitor start
如果出现如下示例信息:

则说明配置成功
vi /etc/rc.d/rc.local后,将上述命令行添加于此
3.5.8重启所有服务器系统后测试
1)在mysql_monitor上执行如下命令,查看各监控机的运行状态
Linux命令行代码:
mmm_control show
得到如下示例结果:
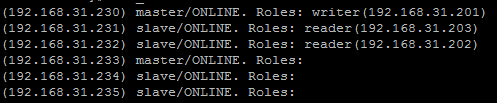
理想情况下,所有的MySQL都应该处于“ONLINE”状态,这里的结果与第1节中的目标清单有一定误差,因为202和203这个“读”IP浮动到slave正好与预期结果相反,这和MySQL的启动顺序有关,而且最重要的是在mmm_common.conf中没有作严格的控制,对于两个slave(231和232)和两个slave_backup(234和235)来说,得到202和203这两个"读"IP的机会是均等的。
现在重新执行2.2.2节的测试场景3),停掉maste后稍等片刻,再执行mmm_control show得到如下结果:

原来的master已处于不可用(HARD_OFFLINE)状态,master_backup(233)成为了新的master,此时再在各slave和slave_backup上执行SHOW SLAVE STATUS;

可以看出,不用再自己手动定位,就可以让Master_Host和Master_Server_Id自动定位到当前处于“ONLINE”状态的Master_Backup上。
1)在Master_Backup上更新数据,在所有的slave和slave_backup上可以很快的查询到最新的数据;
2)重启Master并稍等片刻后,在这台主机上也可以查询到最新的数据,此时writer权限仍在Master_Backup上。
4.最终架构
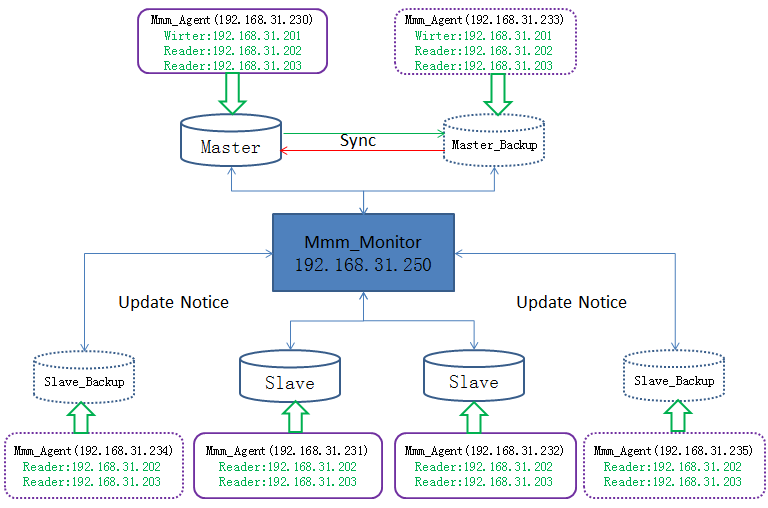
5.总结
接3.5.8测试场景2),虽然Master已恢复了“ONLINE”状态,但整个架构是“非抢占式”的,writer权限仍在Master_Backup上,所以在Master上更新数据不会同步到其它主机上。因此,在实际使用过程中,除进行数据库维护用真实IP访问之外,其余操作都只使用VIP来进行,201为wirter,202和203为reader。
从第4节的架构图中看出,Mmm_Mnitor存在单点问题,当Mmm_Mnitor处于不可运行时,整个主从结构将不能正常运行。可以部署多个监控,结合Keepalived来扩展。
"主-主"和“主-从”架构通常有两个目的:第一是为了进行容灾备份,当数据库发生不可预知的错误导致不可运行甚至丢失数据时,其余的备份机可以继续对外提供数据读写服务。第二是为了分摊数据库压力实现"读写分离"。
读写分离会带来数据延迟达到的问题。假设有一个业务,当数据插入到数据库后要立即又从数据库中将此数据查询出来,因此当数据插入到Master库后,由于网络的延迟,Slave库中不会立即得到这条最新的数据,此时应用程序查询Slave库将得不到预期结果。
通常有如下两个方案解决上述问题:
1)将此类业务控制在一个数据库事务中进行,读写都在master中进行。因此,在mmm_common.conf配置文件中,还需要将db1和db2同时配置在reader组:
Mmm_common.conf配置摘要代码:
<role writer> hosts db1, db4 ips 192.168.31.201 mode exclusive </role> <role reader> hosts db1, db4, db2, db3, db5, db6 ips 192.168.31.202, 192.168.31.203 mode balanced </role>
2)使用Zookeeper来解决分布式一致性问题,后续单独再来介绍。


最新评论: